Contents
Usando IA Gerativa para ir além em seus Trabalhos
Você viu que no correr da disciplina você vai fazer dois maiores trabalhos em computação gráfica avançada, os quais no final você integra em um game:
- O trabalho de modelagem de um ambiente realizado com um modelador avançado, tipicamente Blender, seja de um objeto arquitetônico ou, Como usamos em muitos semestres, o navio Carl Hoepcke (já houve um semestre também em que a modelagem escolhida foi a de uma bicicleta de suspensão traseira de um inventor italiano que morou no Brasil no início do século 20);
- O trabalho de animação de modelos hierárquicos onde você toma um esqueleto animado através de captura de movimentos e integra a um boneco modelado, também em um modelador avançado como Blender, e da vida a este boneco.
No final da disciplina então você integra esses dois trabalhos em um game, desenvolvido com uma game engine da sua escolha, tipicamente Unity, Godot ou UE5, onde o boneco vai se movimentar no ambiente que você modelou e onde você implementa uma jogabilidade mínima, configurando algumas ações que dão pontos ao jogador.
O que este trabalho aqui tem de diferente?
- Você pode tentar usar ferramentas da área da Arte Computacional que utilizam Inteligência Artificial Gerativa.
Nós sugerimos usar variantes de stableDiffusion por ser gratuito e possuir muitas adaptações e especializações que podem ser facilmente usadas para o seu trabalho, inclusive em ambientes como o Google colab, caso você não possua um computador em casa capaz de executar as redes neurais. Mas nada impede você de usar produtos como DALL-E.
Usando stableDiffusion para turbinar o Ambiente do seu Game
O trabalho de modelagem de um ambiente melhorado com IA. Aqui você vai usar a inteligência artificial gerativa para duas coisas:
- Gerar texturas para dar realismo as superfícies dos seus objetos arquitetônicos: ao invés de colar uma textura de parede de tijolos ou muro de pedra pega na internet você vai usar stableDiffusion para criar “imaginações” da aparência dos prédios que você vai utilizar no seu jogo e vai, depois de ter feito a modelagem 3D desses prédios com base na planta baixa, colar estas texturas geradas com stableDiffusion nos prédios que você modelou. Faça a mesma coisa para o “chão” do seu ambiente.
- Gerar texturas de fundo para dar ambiência ao seu jogo: ao invés de você ter um fundo “cor de céu” ou coisa parecida, coloque um cenário apocalíptico com raios e trovões ou outra coisa que você achar que combina com o clima do seu jogo.
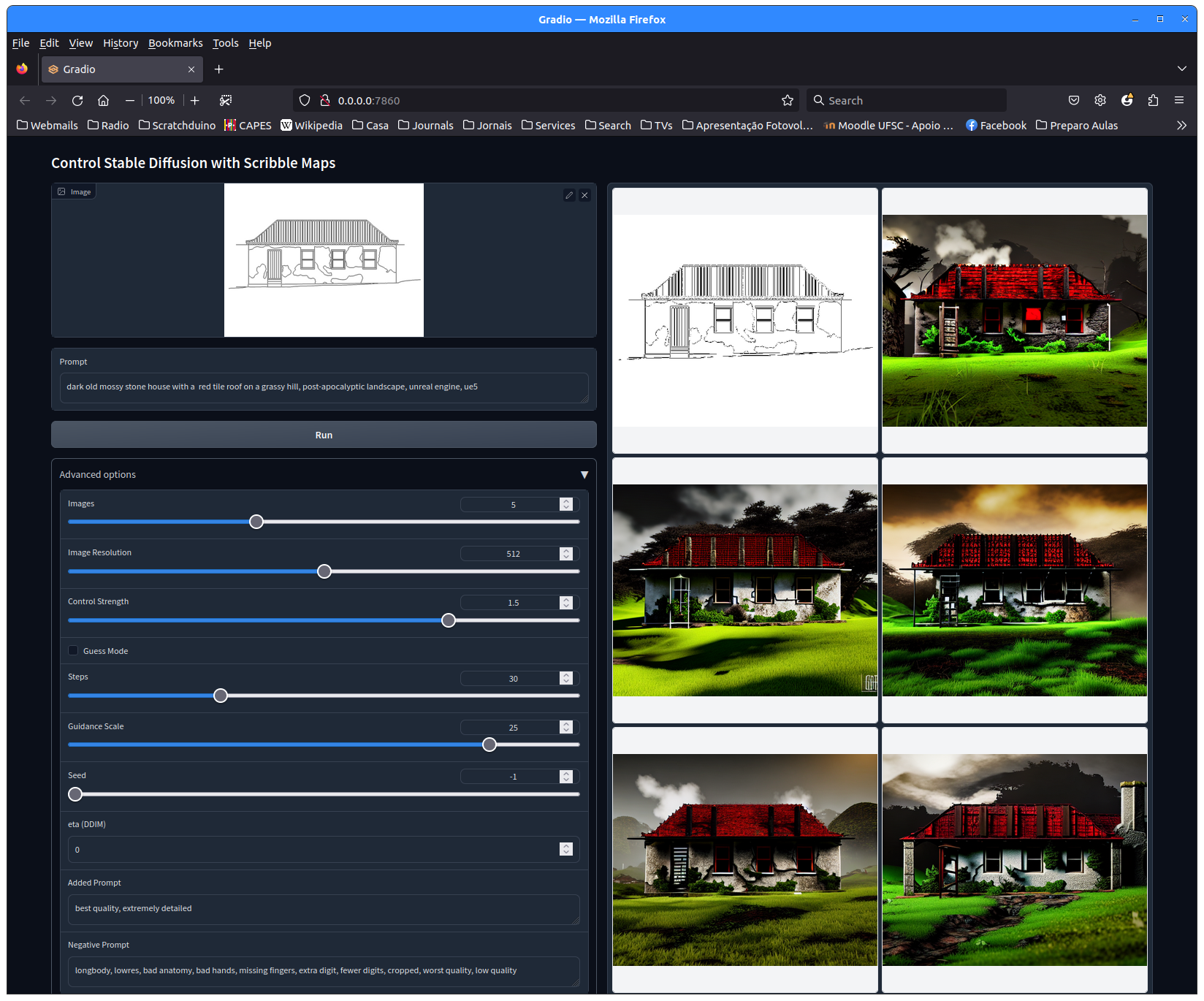
Veja aqui uma imagem da Ponte Hercílio Luz em um cenário pós-apocalíptico gerada com stableDiffusion ControlNet:

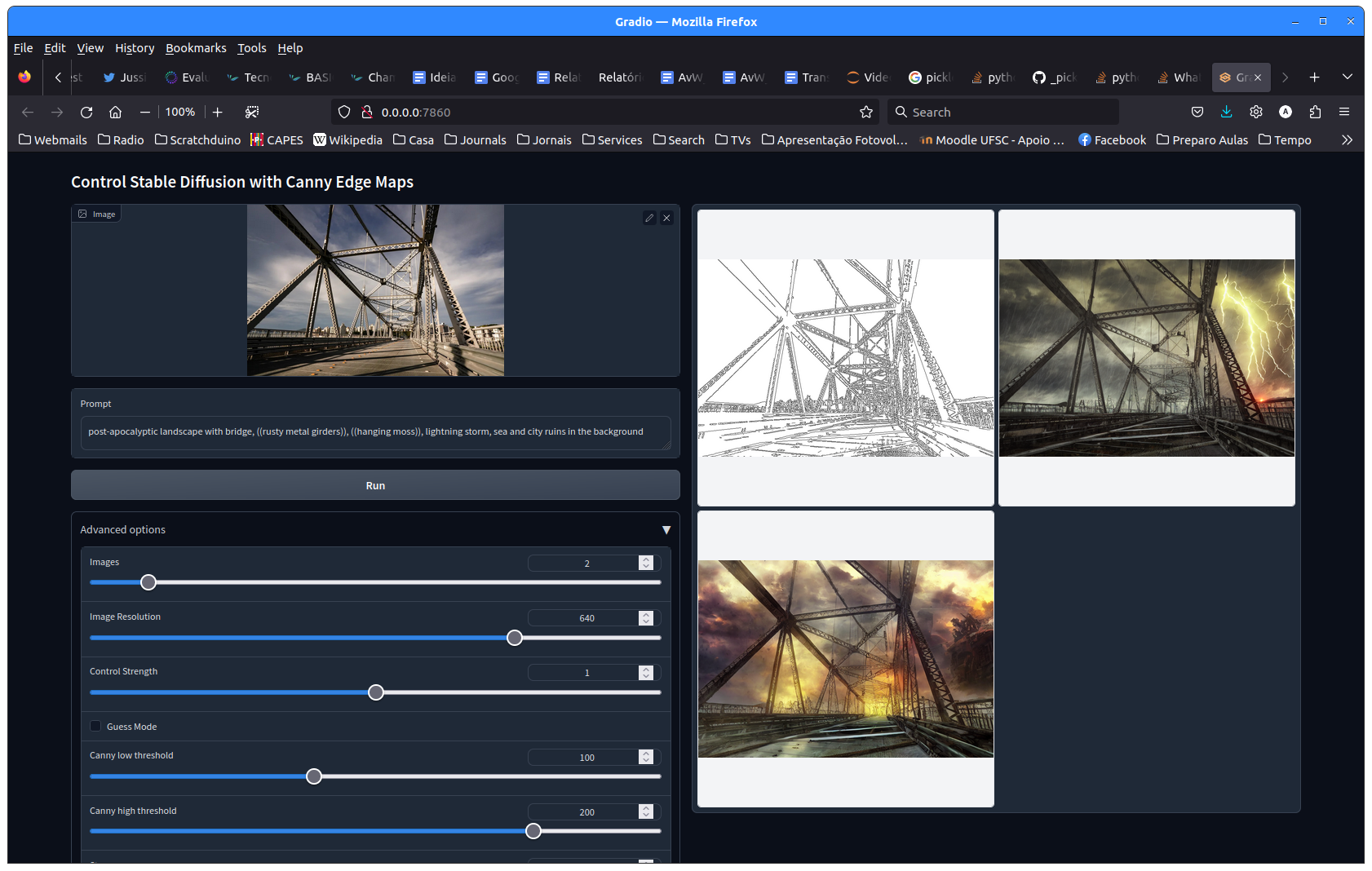
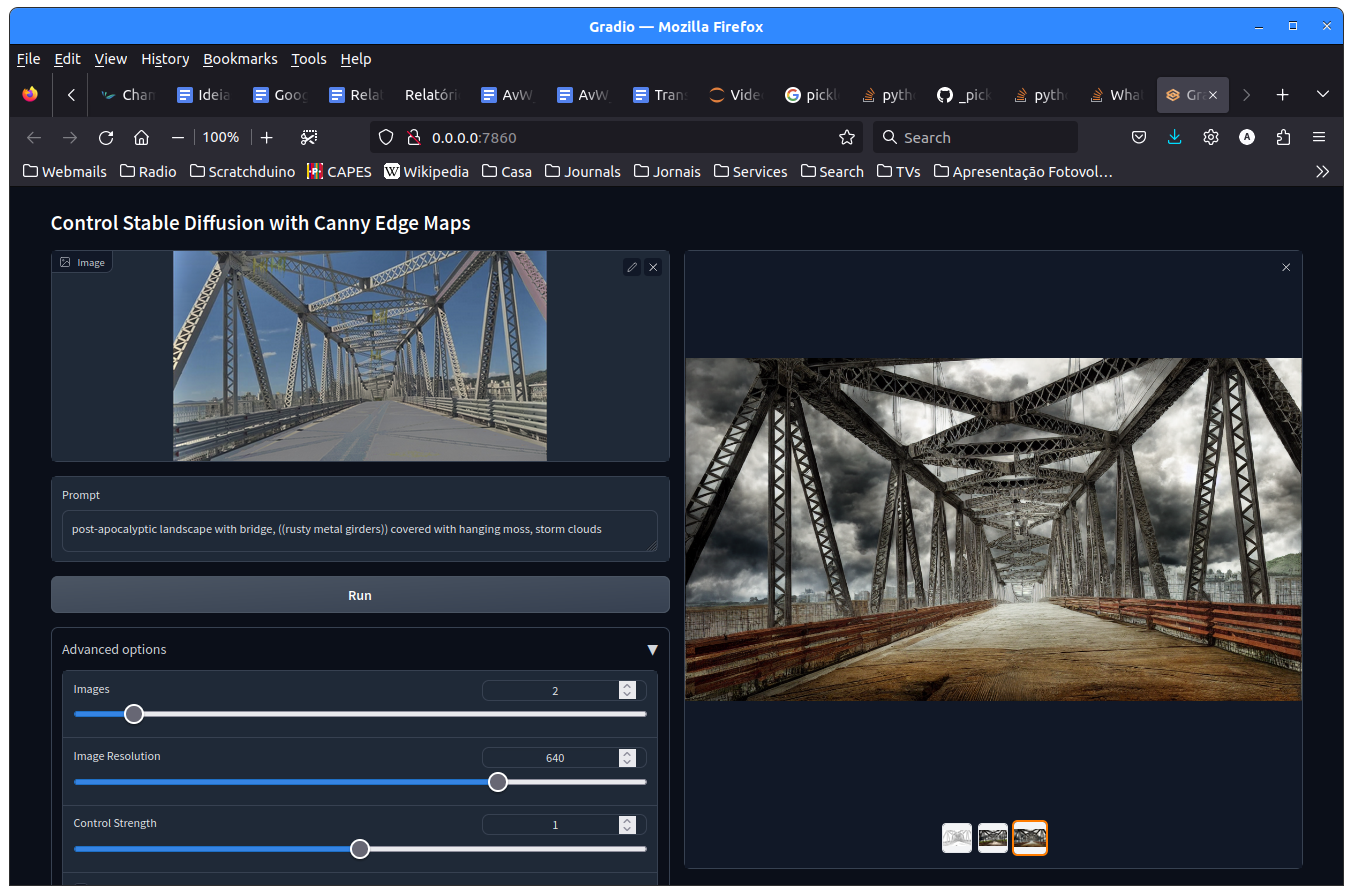
Veja aqui uma imagem da Ponte Hercílio Luz em um cenário pós-apocalíptico com um robô inspirado no Boitatá de Cascaes em primeiro plano:


Produzindo um ambiente para o seu jogo: as fortalezas das Ilhas do Anhatomirim e do Ratão Grande
Como sempre, nós nos inspiramos em alguma coisa da cultura e história locais. Para este trabalho a ideia é que você utilize alguma das fortalezas da Ilha como o ambiente onde o seu jogo vai acontecer. Existe muito material sobre as fortalezas da Ilha organizado digitalmente pela própria UFSC, inclusive arquivos em AutoCad com plantas baixas e fachadas de prédios
- Site com mapas e plantas baixas o tanto da Fortaleza quanto dos prédios: https://fortalezas.org/
- No site acima você vai achar um monte de coisas sobre fortalezas, entre elas a fortaleza da Ilha do Anhatomirim: https://fortalezas.org/?ct=fortaleza&id_fortaleza=1 A Fortaleza de Santa Cruz está localizada na Ilha de Anhatomirim, no atual município de Governador Celso Ramos (Grande Florianópolis), dominando a entrada da Baía Norte da Ilha de Santa Catarina.
- Veja mais aqui: https://projetofortalezasmultimidia.ufsc.br/
- Alternativamente você pode também usar a fortaleza dos Ratones: https://fortalezas.org/?ct=fortaleza&id_fortaleza=2 A Fortaleza de Santo Antônio de Ratones está localizada na Ilha do Ratão Grande, na Baía Norte da Ilha de Santa Catarina, em frente à Praia da Daniela. Projetada e construída pelo Engenheiro Militar, Brigadeiro José da Silva Paes, primeiro governador da Capitania de Santa Catharina (1739-49), a Fortaleza de Ratones é um dos vértices do triângulo defensivo que protegia a Barra Norte da Ilha de Santa Catarina, formado ainda pela Fortaleza de Santa Cruz de Anhatomirim e pela Fortaleza de São José da Ponta Grossa em Jurerê (https://fortalezas.org/?ct=fortaleza&id_fortaleza=12)
Como fazer?
- Siga o material didático da aula sobre a criação de objetos arquitetônicos em Blender disponível em: Criando seu Primeiro Modelo em Blender
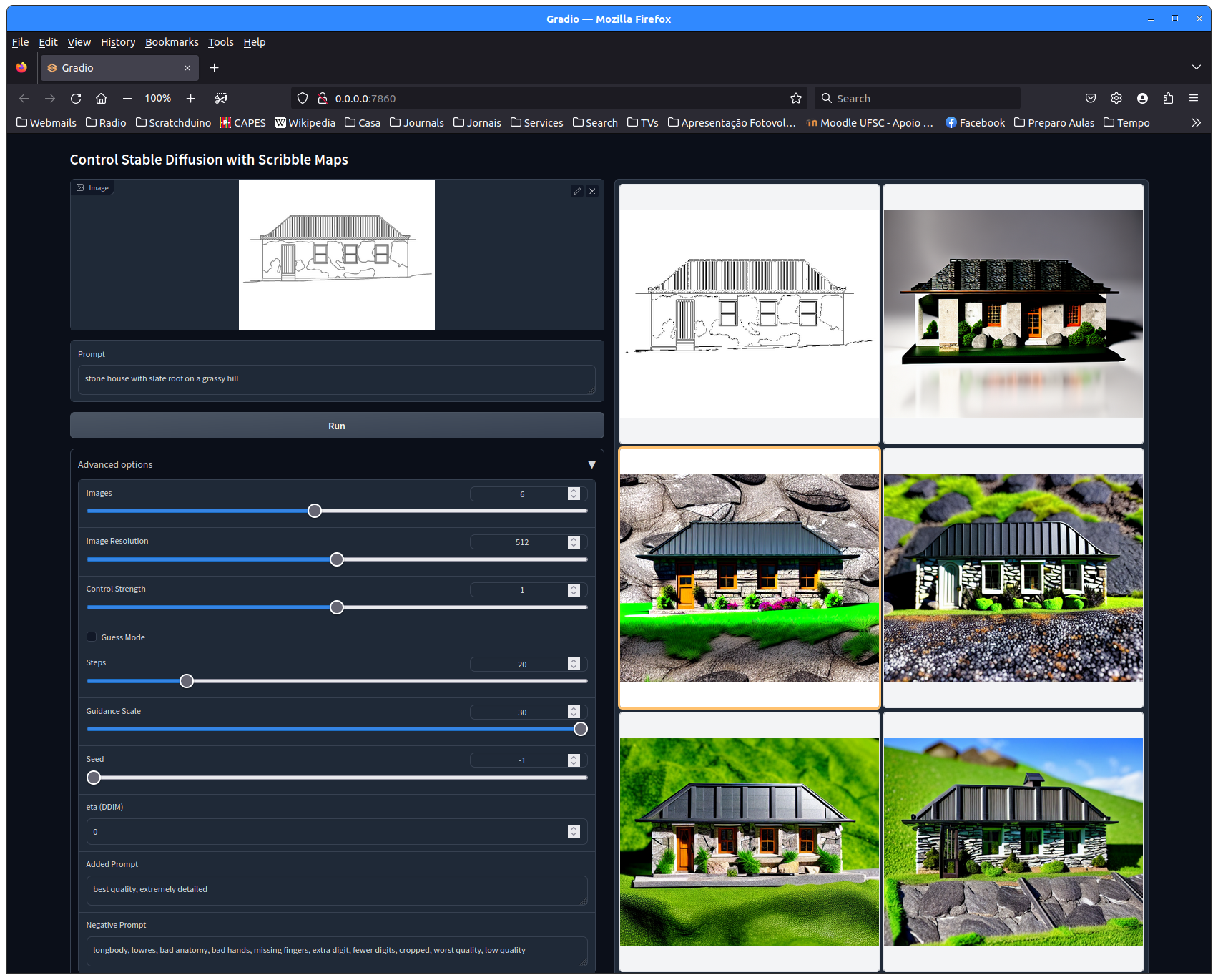
- Utilize a opção ControlNet de stableDiffusion para imaginar visualizações das fachadas dos prédios a partir de figuras geradas a partir das plantas e fachadas;
- Crie panos de fundo e paisagens para dar ambiência ao seu game utilizando também a IA gerativa;
- Para criar a estrutura do seu prédio com base na planta baixa ou na modelagem AutoCAD da fachada, siga o tutorial de como utilizar plantas e desenhos para gerar objetos em ambientes 3D disponível no enunciado deste trabalho aqui: Modelagem Realista de um Navio Histórico de Florianópolis com base em seu Projeto
- Modeling a ships hull in Blender (baseado em uma planta desenhada…) – https://www.youtube.com/watch?v=vtMuy1gUSf8
- Recorte as texturas ou a fachada inteira dessas imagens geradas com a inteligência artificial gerativa e utilize as como textura no seu modelo 3D: Aplicando Texturas em Blender

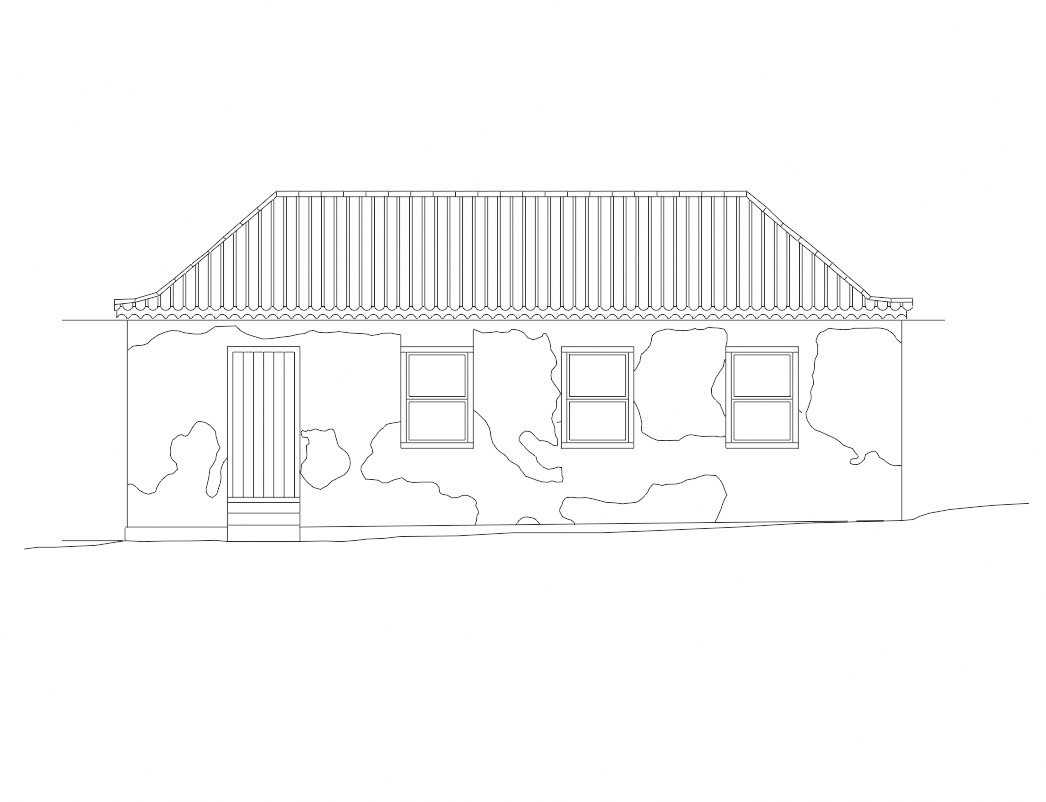
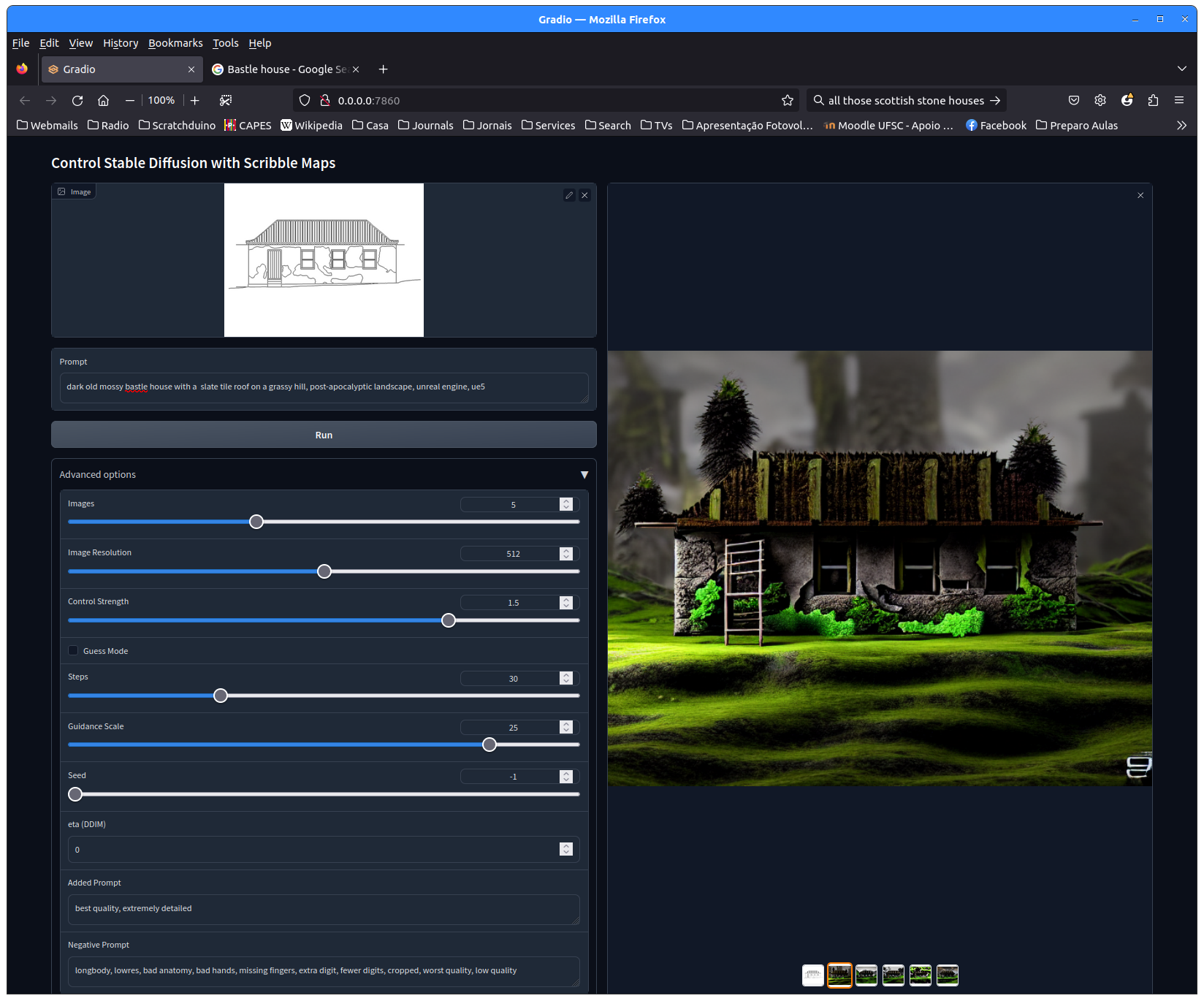
Adiante alguns exemplos da fachada do “armazém da praia” da Fortaleza da Ilha do Anhatomirim re-imaginada pelo stableDiffusion:
O gamer finlandês Jussi Kemppainen tem feito bastante experimentos tanto na criação de personagens quanto na criação de ambientes para games utilizando Inteligência Artificial gerativa e tem publicado alguns tutoriais e relatos de suas experiências online. Dê uma olhada no material abaixo: https://echoesofsomewhere.com/2023/05/17/the-labyrinth-part-1/
Usando stableDiffusion para ajudar a gerar o seu personagem
Vamos usar Inteligência Artificial gerativa tanto para sugerir uma aparência para o seu personagem como para gerar as texturas que depois você vai utilizar para prover realismo ao seu boneco. Os movimentos do boneco serão resultado da nossa atividade de captura de movimentos no laboratório TECMIDIA. Temos uma grande biblioteca de captura de movimentos disponível em e também estamos capturando novos todo semestre.
O tema do seu personagem será o imaginário de Franklin Cascaes. Para ver mais sobre essa ideia olhe a nossa página sobre o projeto: cyberCascaes – a arte de Franklin Cascaes reimaginada por uma inteligência artificial
Como fazer?
- Siga o material didático da aula sobre a criação de personagens em Blender disponível em: Criando Personagens em Blender. Comece escolhendo um personagem do acervo de Franklin Cascaes ou de outra fonte;
- Utilize a opção img2img de stableDiffusion (preferencialmente utilizando a interface gráfica AUTOMATIC1111) para imaginar visualizações de robôs inspirados em personagens de Franklin Cascaes;
- Utilize a forma corporal das imagens de robôs geradas para criar modelos 3D do seu personagem. O gamer finlandês Jussi Kemppainen tem feito bastante experimentos tanto na criação de personagens quanto na criação de ambientes para games utilizando Inteligência Artificial gerativa e tem publicado alguns tutoriais e relatos de suas experiências online. Dê uma olhada no material adiante: https://echoesofsomewhere.com/2023/05/17/the-labyrinth-part-1/
- Importe para o Blender e registre o esqueleto e os movimentos das seqüências de MoCap que você escolheu para os movimentos do seu personagem. Lembre-se que o enunciado do modelo hierárquico pede pelo menos duas seqüências de movimento diferentes, como andar, correr, chutar, lutar, etc.
- Recorte as texturas dessas imagens geradas com a inteligência artificial gerativa e utilize as como textura no seu modelo 3D;
…agora é só importar do Blender para o game engine!

Como nós vamos avaliar?
Uso de Arte Computacional por meio de Inteligência Artificial Gerativa na Computação Gráfica não está previsto no nosso Programa de Ensino e por isso as tarefas descritas aqui são opcionais e a sua execução conta até 2 pontos adicionais tanto na tarefa de Modelagem com Blender quanto na tarefa de Personagem com Modelo Hierárquico em Game Engine.
Critérios de avaliação adicionais em cada um dos dois trabalhos:
- +1 ponto na nota do trabalho: Grupo fez uso efetivo de técnicas de inteligência artificial gerativa na criação de um personagem ou de texturas para objetos arquitetônicos/panos de fundo/paisagens (deve estar documentado no seu documento final de descrição do game com o processo de geração do modelo, preferencialmente através de imagens intermediárias e capturas de tela da geração)
- +1 ponto na nota do trabalho: Grupo conseguiu resultados convincentes e realistas com uma melhora da qualidade do realismo do game, em linha e comparável a exemplos disponibilizados em fóruns e redes sociais (eu sei que esse critério é subjetivo, mas fica difícil avaliar qualidade em Arte Computacional de outra forma…)
Observe estes pontos adicionais podem ser obtidos tanto no trabalho de modelagem 3D quanto no trabalho de personagem com o modelo hierárquico em game, os pontos que você obtiver aqui não vão se refletir sobre a sua nota no sistema gráfico interativo que é um trabalho de programação manual.
P.S.: os arquivos do projeto fortalezas multimídia são todos em AutoCad e não em bitmaps. Para poder gerar imagens que você possa utilizar tanto com o tutorial de criação de objetos 3D com base em plantas e fachadas quanto para usar como semente para a geração de uma visualização com inteligência artificial gerativa você precisa carregar os projetos AutoCAD em alguma visualizador gratuito (há muitos na internet, alguns funcionam online, outros você pode instalar no seu computador) e exportar a visualização na forma de imagem, como é o caso do Armazém da Praia, acima. Isso dá algum trabalho e nós sugerimos que você contate os seus colegas e vocês dividam esse trabalho e depois compartilhem as imagens, enviando-as também ao professor, para que ele possa disponibilizar online e nos próximos semestres a turma não tenha esse trabalho de novo.
Material no Medium & Redes Sociais sobre stableDiffusion
Páginas Explicativas
- Tutorials For How To Use Stable Diffusion on Google Colab & PC By Automatic1111 Web UI – Install, Run, DreamBooth & Textual Inversion Training, Custom…. https://huggingface.co/andite/anything-v4.0/discussions/37
- The Illustrated Stable Diffusion – https://jalammar.github.io/illustrated-stable-diffusion/
- What Is Stable Diffusion and How Does It Work? – https://www.vegaitglobal.com/media-center/knowledge-base/what-is-stable-diffusion-and-how-does-it-work
- Stable Diffusion Clearly Explained! How does Stable Diffusion paint an AI artwork? Understanding the tech behind the rise of AI-generated art – https://medium.com/@steinsfu/stable-diffusion-clearly-explained-ed008044e07e
- How Stable Diffusion works, explained for non-technical people – https://bootcamp.uxdesign.cc/how-stable-diffusion-works-explained-for-non-technical-people-be6aa674fa1d
- Stable Diffusion Art::How does Stable Diffusion work? https://stable-diffusion-art.com/how-stable-diffusion-work/
- Stable Diffusion – coleção de material no Medium – https://medium.com/tag/stable-diffusion
- https://twitter.com/StabilityAI
- Introduction to Diffusion Models for Image Generation – A Comprehensive Guide https://learnopencv.com/image-generation-using-diffusion-models/
- Stable Diffusion 2.0 Released — This Is Massive – https://medium.com/mlearning-ai/stable-diffusion-v2-0-released-this-is-massive-718072bc57e1
- Understanding Diffusion & Stable Diffusion in AI – https://medium.com/tech-blogs-by-nest-digital/understanding-diffusion-stable-diffusion-in-ai-113f32c977f3
- 5 Websites To Try Stable Diffusion 2.0 – https://medium.com/mlearning-ai/5-websites-to-try-stable-diffusion-2-0-6d3dbddda47
- DreamStudio is the official web app for Stable Diffusion from Stability AI – https://beta.dreamstudio.ai/dream
- Replicate is a platform for sharing and using ML models via API. The test app for SD 2.0 is from cjwbw (https://replicate.com/cjwbw) – https://replicate.com/about
- PlaygroundAI is an image-generator web app with a feature-rich tools and fast generation – https://playgroundai.com/
- Anzor Qunash made a Stable Diffusion 2.0 Colab notebook – https://colab.research.google.com/github/qunash/stable-diffusion-2-gui/blob/main/stable_diffusion_2_0.ipynb
- BasetTen is an MLOps platform for startups to rapidly develop, deploy, and test models in production – https://www.baseten.co/
- Comparação SD2, Dall-E e MJ4
- Stable Diffusion 2 VS MidJourney 4 – Same Prompt, Different Results – https://medium.com/mlearning-ai/stable-diffusion-2-vs-midjourney-4-same-prompt-different-results-ccb2398d30d5
- Generating images using Dall-E 2 vs Stable Diffusion 2.1 – https://balabala76.medium.com/generating-images-using-dall-e-2-vs-stable-diffusion-2-1-2f814dd6d6e7
- Instalando e Rodando em Casa
- A Simple Way To Run Stable Diffusion 2.0 Locally On Your PC – No Code Guide – https://medium.com/geekculture/a-simple-way-to-run-stable-diffusion-2-0-locally-on-your-pc-no-code-guide-3beb911e444c
- One Click Install For Stable Diffusion UI 2.0 — Run Locally – https://medium.com/mlearning-ai/one-click-install-for-stable-diffusion-ui-2-0-run-locally-3c38bfbd30cd
- An Easy Way To Run Stable Diffusion With GUI On Your Local Machine (Gradio UI and optimized version of Stable Diffusion that use less VRAM) – https://medium.com/geekculture/an-easy-way-to-run-stable-diffusion-with-gui-on-your-local-machine-3a7812fe1b81
- Run Stable Diffusion AI v.1 at Home – No Code Guide (command line) – https://medium.com/geekculture/run-stable-diffusion-in-your-local-computer-heres-a-step-by-step-guide-af128397d424
Inpainting
A inteligência artificial gerativa para criação de imagens introduziu um novo termo no processo de criação de imagens digitais: inpainting. Inpainting pode ser definido como a introdução inteligente de um texto descrevendo uma sub-imagem em uma outra imagem através do uso de inteligência artificial gerativa, com o objetivo de refinar um detalhe dessa imagem.
Neste processo você manualmente seleciona a região da imagem-alvo que deve receber a sub-imagem objeto e a inteligência artificial gerativa usa os conhecimentos e informações nela treinados para gerar, adaptar e harmonizar a imagem objeto à imagem-alvo maior, de forma que ela pareça fazer “naturalmente” parte da imagem-alvo, com as suas fronteiras se integrando ao contexto iconográfico ao seu redor. A imagem objeto pode ser uma coisa simples como um rosto que é, de forma “inteligente”, substituído na imagem-alvo, quanto toda uma sub-cena de uma cena maior. Tanto o texto que vai gerar a imagem alvo quanto a imagem objeto podem ter sido previamente geradas utilizando-se inteligência artificial gerativa. Uma forma de arte digital baseada em inteligência artificial gerativa que faz uso massivo de inpainting é a geração de stelfies – veja mais adiante.
Utilizar inpainting na prática é uma coisa não tão trivial e abaixo oferecemos alguns tutoriais disponíveis na Internet:
- Beginner’s guide to inpainting (step-by-step examples) (tutorial oficial da Stable Diffusion Art) – https://stable-diffusion-art.com/inpainting_basics/ – este tutorial utiliza o ambiente AUTOMATIC1111 que aconselhamos usar, caso você possua em casa um computador capaz de rodar stableDiffusion, e explicamos nas seção sobre interfaces web para stableDiffusion mais adiante;
- Stable Diffusion Inpainting Tutorial – https://hashdork.com/stable-diffusion-inpainting-tutorial/
- Stable Diffusion Inpainting tutorial: Prompt Inpainting with Stable Diffusion – https://lablab.ai/t/stable-diffusion-inpainting
- https://huggingface.co/lambdalabs/image-mixer
Refinamento do treinamento e DreamBooth
Existem várias redes neurais generativas pré-treinadas, de código aberto e uso gratuito, todas elas derivadas do stableDiffusion original. Nos exemplos desta aula aqui nós estamos usando as redes stableDiffusion 1.5, 2.0 e 2.1. As versões mais novas de stableDiffusion foram treinadas no conjunto de dados LAION (veja a explicação mais abaixo), que não necessariamente é um conjunto de dados que possui muitas coisas da temática aqui da Ilha de Santa Catarina que nós abordamos nos games e animações que fazemos na nossa disciplina.
Por exemplo, se você tentar convencer stableDiffusion, não importa em qual versão, a criar uma imagem da Ponte Hercílio Luz, o resultado vai sempre se parecer com alguma ponte que deve figurar repetidamente no conjunto LAION, notadamente a ponte Golden Gate (se você no seu prompt insistir que se trata de uma ponte pênsil) ou a ponte do Brooklin (se você insistir que se trata de uma ponte urbana em uma grande capital)… Esse viés é natural porque a rede neural só vai conseguir gerar aquilo que ela aprendeu.
Como mudar isso? Redes neurais de aprendizado profundo permitem, ao contrário daquelas antigas redes Backpropagation, ter o seu treinamento refinado. Na terminologia de aprendizado profundo, isso é chamado de fine-tuning. Para isso você continua a treinar a rede, “congelando” uma parte dela e treinando apenas a parte de entradas e saídas com os novos conceitos que você deseja que ela aprenda. Como muitas coisas de cunho geral ela já aprendeu, com essa sintonia fina da rede é possível fazer com que ela “saiba” agora os detalhes desses novos conceitos.
Existem basicamente duas maneiras de fazer isso:
- Continuar o treinamento da rede no modo fine-tuning, utilizando tanto um conjunto grande de novas imagens quanto um novo arquivo JSON com as legendas em texto para cada uma dessas imagens. Essa é a forma mais complicada e você vai precisar de um computador poderoso ou vai ter que rodar esse treinamento em uma plataforma na nuvem como o Google Colab, vast.ai, HuggingFace ou Paperspace. Esse processo só é interessante se você quiser treinar todo um novo universo de conceitos na rede.
- Realizar um fine-tuning específico para que a rede aprenda apenas um único conceito novo. Esse é um processo bem mais simples e você só necessita de uma mão cheia de imagens desse novo conceito e de uma única legenda descrevendo o conteúdo de todas essas imagens. Esse processo foi denominado pelos autores de “balcão de sonhos” ou DreamBooth: você vai ensinar a rede a “sonhar” imagens com um novo elemento dentro delas.
O primeiro processo extrapola o contexto de uma disciplina de graduação e não vamos tratar aqui. Instruções para você fazer o DreamBooth vão abaixo:
- How to use DreamBooth to put anything in Stable Diffusion (tutorial original de stableDiffusion Art) – https://stable-diffusion-art.com/dreambooth/
- How To Run DreamBooth With Stable Diffusion Locally — A Step-By-Step Guide (ensina como você pode instalar e usar a extensão DreamBooth da plataforma AUTOMATIC1111) – https://medium.com/mlearning-ai/how-to-run-dreambooth-locally-a-step-by-step-gyu-88c028ab01a4
- DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (artigo científico descrevendo os princípios do processo) – https://arxiv.org/abs/2208.12242
- Os Gits abaixo são versões levemente diferentes da mesma coisa, com diferentes adaptações, se você vai rodar em casa ou no Google colab e não quiser usar AUTOMATIC1111, dê uma olhada com atenção em todos:
- https://github.com/ShivamShrirao/Dreambooth-Stable-Diffusion
- https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
- https://github.com/JoePenna/Dreambooth-Stable-Diffusion
- https://github.com/replicate/dreambooth (código de um provedor de nuvem que pode ser usado para rodar em casa se você tiver coragem)
- Se você quiser gastar o dinheiro, existem provedores de processamento na nuvem que oferecem instalações prontas de DreamBooth e permitem a você gerar uma nova rede neural por um custo relativamente baixo.
- How to Inject Your Trained Subject e.g. Your Face Into Any Custom Stable Diffusion Model By Web UI
Se você está mesmo interessado em passar trabalho e quiser realizar uma sintonia fina da rede inteira e fazê-la aprender uma meia dúzia de conceitos novos todos de uma vez e tiver a paciência de gerar um conjunto grande de dados para descrever esses conceitos, então você pode usar a opção de realizar treinamento de sintonia fina da rede que vem junto com AUTOMATIC1111. Esteja preparado para treinar a rede neural por muito tempo… Lembre-se também que se você obtiver as suas imagens utilizando um web crawler, você deve se certificar que as imagens não possuem restrições de uso que o impeçam de usá-las aqui na nossa disciplina.
Imagens para 3D
- HuggingFace Zero-1-to-3: Zero-shot One Image to 3D Object – https://huggingface.co/spaces/cvlab/zero123-live
- This live demo allows you to control camera rotation and thereby generate novel viewpoints of an object within a single image.
- It is based on Stable Diffusion. Check out our project webpage and paper if you want to learn more about the method!
- Note that this model is not intended for images of humans or faces, and is unlikely to work well for them.
- https://zero123.cs.columbia.edu/
- https://github.com/cvlab-columbia/zero123
- Stable-Dreamfusion – A pytorch implementation of the text-to-3D model Dreamfusion, powered by the Stable Diffusion text-to-2D model – https://github.com/ashawkey/stable-dreamfusion
Vídeo com stableDiffusion
- TemporalNet And Stable Diffusion: The Next Game-Changer For AI Video Creation? https://bootcamp.uxdesign.cc/temporalnet-and-stable-diffusion-the-next-game-changer-for-ai-video-creation-57d8cf2bc410