 Redes para detecção e localização de objetos em cenas
Redes para detecção e localização de objetos em cenasContents
- 1 Detecção de Objetos & Segmentação Baseada em Regiões
- 1.1 Classificadores de Regiões associados a Extratores de Características baseados em CNN
- 1.2 Redes Neurais Convolucionais de Disparo Único (Single Shot Detection) para Reconhecimento de Objetos
- 1.3 RetinaNet
- 1.4 Detecção de Objetos Integrada à Segmentação Semântica
- 2 Aplicações no Browser ou com JavaScript
- 3 Model Zoos em outros Frameworks
- 4 Como avaliar e validar a qualidade do seu modelo?
Detecção de Objetos & Segmentação Baseada em Regiões
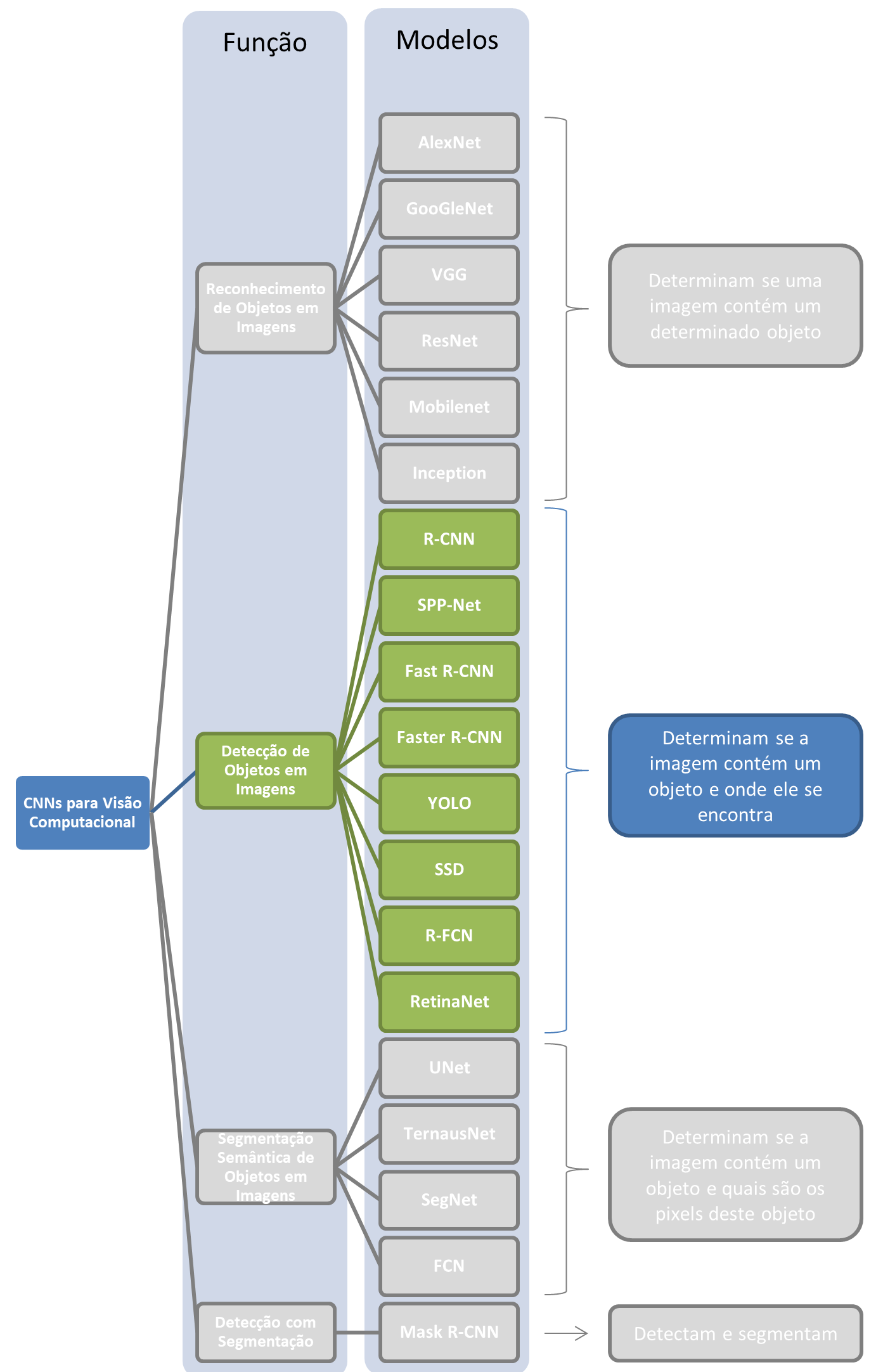
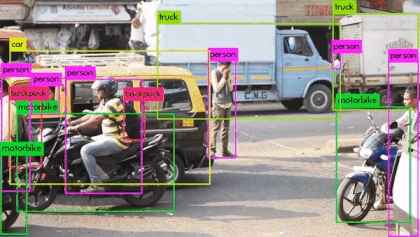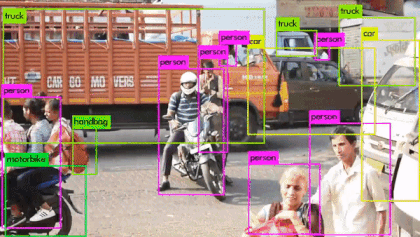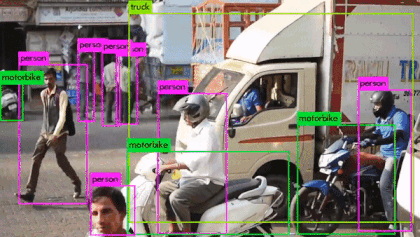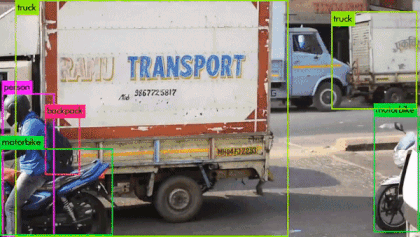
Estes são modelos de redes neurais que servem tanto para (a) identificar objetos e como (b) a região onde os objetos se encontram. Tipicamente a saída dessas redes é um casco convexo retangular (bounding box) que registra a região de maior confiança da presença do objeto detectado (vide imagem do campus da UFSC no topo desta página). Estas redes podem ser utilizadas tanto para
- detecção de objetos em imagens como para
- identificação grosseira de seu número e sua localização.
Nesse snetido essas redes, por localizarem um objeto e permitirem, através do bounding box, a realização da segmentação da subimagem onde o objeto de interesse se encontra, podem ser classificadas tanto como redes de reconhecimento de objetos como redes de segmentação de objetos. Nesta disciplina nós vamos tratá-las como redes de identificação de objetos com concomitante localização do obejto na cena, não as considerando redes de segmentação.
Existem duas variantes principais dessas redes:
- Classificadores de regiões associados a extratores de características baseados em CNN: R-CNN, Faster-R-CNN, etc
- Redes neurais convolucionais de disparo único para econhecimento de objetos: YOLO, etc
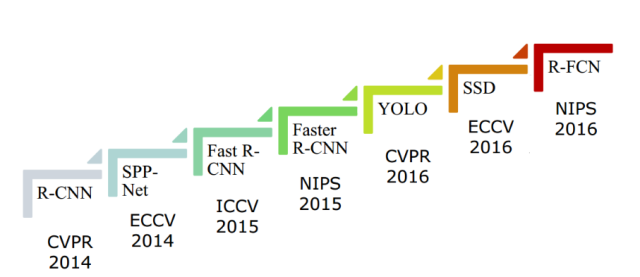
Esta é uma área que cresceu muito nos últimos anos. A figura abaixo provê uma visão geral da quantidade de novos modelos de redes neurais que foram desenvolvidos, classificando-as por anos de publicação e por conferência em que foram apresnetadas pela primeira vez:
Classificadores de Regiões associados a Extratores de Características baseados em CNN
Vamos prover uma breve revisão histórica dos modelos.
O problema da Detecção de Objetos em CNN
A diferença entre métodos de classificação de objetos (como as redes da seção anterior) e métodos de detecção de objetos, é que na detecção de objetos você deseja:
- identificar quantos objetos de uma determinada categoria se encontram na imagem;
- identificar onde na imagem cada objeto se encontra.
Tipicamente não se sabe de antemão quantas instâncias de uma determinada categoria de objeto você vai identificar em uma cena. Se você fosse construir uma CNN padrão para resolver este problema, você acabaria com a seguinte situação: o tamanho da saída é variável e depende de quantas instâncias de um objeto você vai encontrar e onde estão, o que não é possível em uma rede com uma camada de saída de tamanho fixo. Para isso foram desenvolvidos modelos como R-CNN e YOLO.
R-CNN: Regions with CNN feature
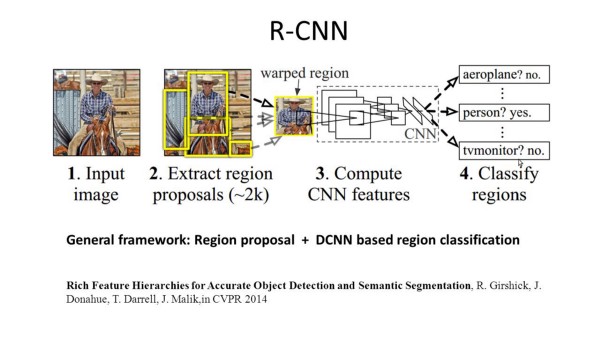
R-CNN executa segmentação com base nos resultados da detecção de objetos. R-CNN inicialmente usa busca seletiva para extrair uma grande quantidade de candidatos e então calcula as características para cada um deles através de CNN. Por fim classifica cada região usando um classificador linear específico, geralmente SVM (suport vector machines). Ao contrário das redes discutidas na seção anterior, R-CNN é capaz de executar tarefas mais complexas, como detecção de objetos e segmentação grosseira de imagens. Uma R-CNN pode ser construída sobre qualquer das redes de classificação de imagens tradicionais, como AlexNet, VGG, GoogLeNet e ResNet.
R-CNN resolve o problema das múltiplas saídas usando uma Busca Seletiva da seguinte forma:
1. Generate initial sub-segmentation, we generate many candidate regions
2. Use greedy algorithm to recursively combine similar regions into larger ones
3. Use the generated regions to produce the final candidate region proposals
R-CNN gera inicialmente em torno de 2000 candidatos usando o algoritmo acima, que é baseado em técnicas simples de visão computacional tradicional. A partir daí:
- Cada candidato é reformatado para uma imagem quadrada de tamanho padrão;
- Imagem é alimentada a uma rede neural que gera vetores de características de 4096 dimensões como saída;
- Uma SVM classifica o vetor de características produzindo duas saídas:
- uma classificação
- uma indicação de desvio (offset) que pode ser usada para ajustar o bounding box.
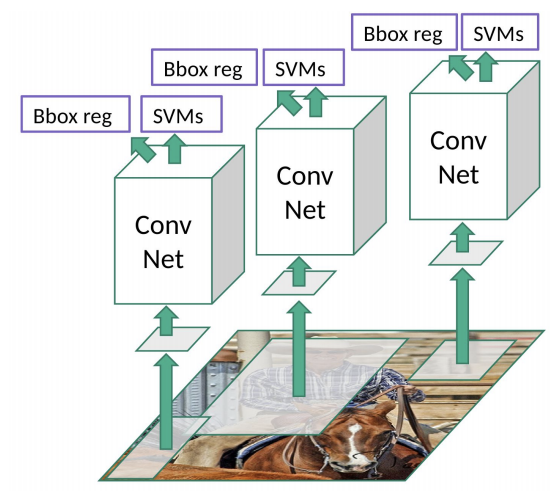
Desvantagens do modelo:
- Lento para treinar: o treino é em dois estágios;
- Lentíssimo para executar: para cada imagem a R-CNN primeiramente classifica 2000 subimagens.
Links
- Apresentação: https://courses.cs.washington.edu/courses/cse590v/14au/cse590v_wk1_rcnn.pdf
- Artigo original: Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
- Preprint do arXiv: https://arxiv.org/abs/1311.2524
- Git original dos autores: https://github.com/rbgirshick/rcnn (MATLAB e Caffe)
Fast-R-CNN: Fast Region-based Convolutional Networks for object detection

Em um artigo no ano seguinte, os autores da R-CNN apresentaram uma solução que resolve os problemas de lentidão do enfoque baseado na análise de 2000 imagens semi-randômicas do R-CNN: preprocessamento convolucional.
Ao invés de alimentar a rede neural com imagens-candidatas, a imagem inteira é alimentada à rede para a geração de um mapa de caracterísiticas convolucionais (CFM – convolutional feature map). Este CFM é então usado para a busca por regiões-candidatas, que são reformatadas em imagens quadradas de tamanho fixo através de uma camada de pooling de região de interesse (RoI pooling). A partir do vetor de características gerado para cada RoI é realizada uma classificação com uma camada softmax, que prediz a categoria do objeto e a associa ao bounding box dado pelo quadrado de origem.
O gráfico abaixo mostra uma comparação entre os dois enfoques e uma outra rede da mesma época, a SPP-Net (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition):

Links
- Git original dos autores: https://github.com/rbgirshick/fast-rcnn (Caffe)
- Outra versão dos autores: https://github.com/rbgirshick/caffe-fast-rcnn
- Preprint do artigo original no arXiv: Fast R-CNN
Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
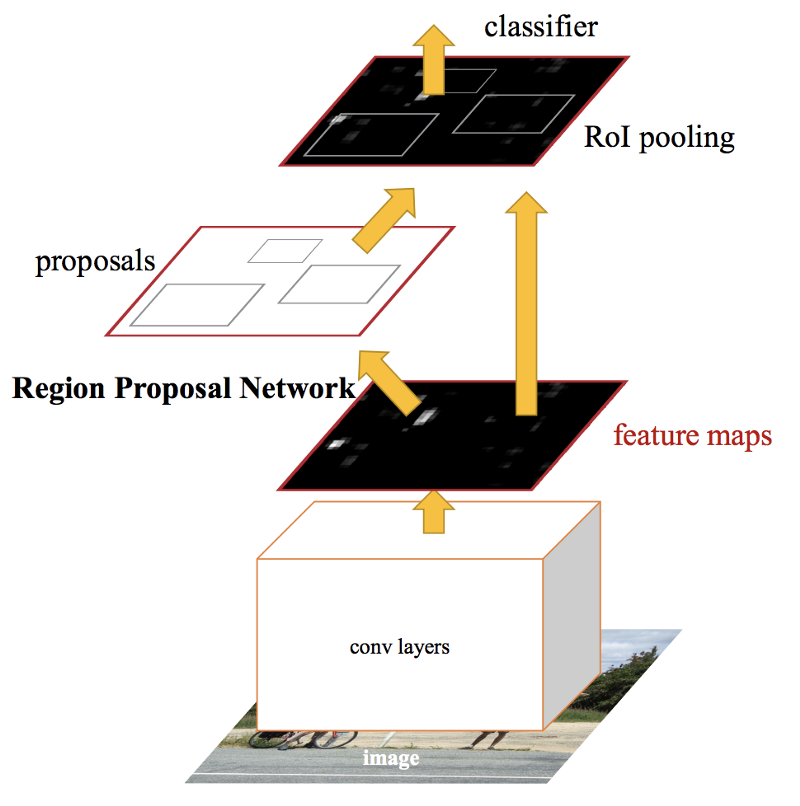
Uma solução encontrada, novamente parcialmente pelos mesmos autores, para tornar a rede ainda mais rápida, foi eliminar a busca seletiva por regiões de interesse. Similarmente à Fast R-CNN, a imagem é usada diretamente como entrada para gerar um mapa de características convolucional. Neste modelo, porém, ao invés de realizar uma busca seletiva sobre este mapa, uma segunda rede neural, separada, é usada para predizer regiões candidatas. É chamada de Region Proposal Network (RPN). RPN usa uma mini-rede neural baseada em uma janela deslizante que analisa a imagem de entrada e é invariante a translação. Para evitar excesso de propostas, supressão de não-máximos é realizada já neste estágio.
Essas regiões-candidatas, da mesma forma que no Fast-R-CNN, são reformatadas em imagens quadradas de tamanho fixo através de uma camada de pooling de região de interesse (RoI pooling). A partir do vetor de características gerado para cada RoI é realizada uma classificação com uma camada softmax, que prediz a categoria do objeto e a associa ao bounding box dado pelo quadrado de origem.
A imagem abaixo mostra uma comparação entre os três modelos dos autores e a SPP-Net:

Links
- Git dos autores: https://github.com/rbgirshick/py-faster-rcnn
- Preprint no arXiv: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Medium::Faster R-CNN (object detection) implemented by Keras for custom data from Google’s Open Images Dataset V4
Redes Neurais Convolucionais de Disparo Único (Single Shot Detection) para Reconhecimento de Objetos
Os enfoques acima usam foco em sub-regiões da imagem para identificar objetos. A rede nunca olha para a imagem como um todo. Aqui vamos ver enfoques que consideram a imagem como um todo.
You Only Look Once: YOLO
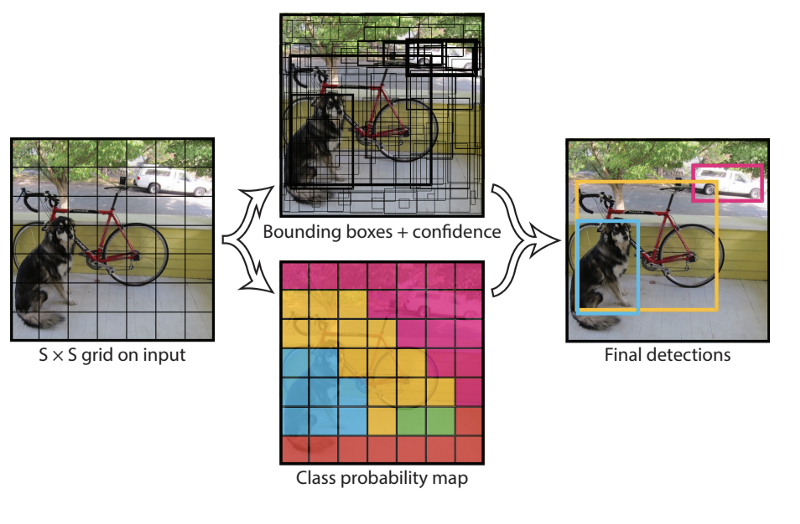
Em YOLO uma única rede convolucional prediz tanto os bounding boxes quanto as probabilidades de pertinencia a classe de cada objeto detectado. Para isso, YOLO funciona da seguinte forma:
- toma-se uma imagem e divide-se-a em um grid SxS de células;
- usando o grid como referência, gera-se m bounding boxes;
- bounding boxes com probabilidade acima de um limiar são selecionados e usados para localizar o objeto dentro da imagem.
YOLO muito mais rápido (45 fps no set dos autores -> até duas ordens de grandeza) mais rápido do que algoritmos contemporâneos. Sua maior falha é inacurácia com objetos pequenos na imagem.
Cada célula do grid é usada para predizer B bounding boxes (bbox) e C probabilidades de classe. Uma predição de bbox possui 5 componentes: (x, y, w, h, confiança). As coordenadas (x, y) representam o centro do bbox relativo à localização da célula (se o centro de um bbox não cair em uma célula ela não será responsável por ele e não vai representá-lo -> células só possuem uma referência a objetos cujo centro cair dentro delas). Essa coordenadas são normalizadas para [0, 1]. As dimensões do bbox (w, h) também são normalizadas para [0, 1], relativamente ao tamanho da imagem.
Suponha que você dividiu uma imagem de 448×448 pixels em um grid de SxS = 3×3 células:
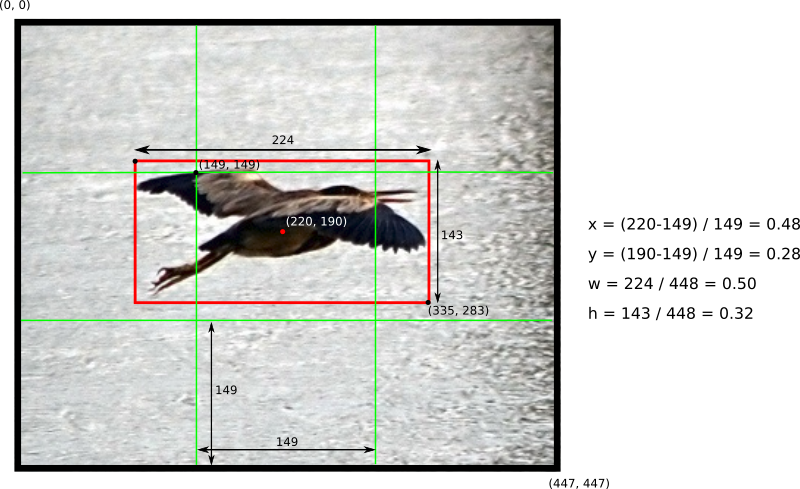
Em YOLO, o conceito de interseção sobre união (IoU) tem um papel importante: a confiança de uma predição em YOLO é dada por: Pr(Object) * IOU(pred, truth).
Links:

YOLO.V2 (YOLO 9000) em Keras (YAD2K)
- LearnOpenCV::Satya Mallick: Deep Learning based Object Detection using YOLOv3 with OpenCV | Learn OpenCV
- Medium::Jonathan Hui::Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3
- GitHub:: Deep-Learning-for-Tracking-and-Detection – Collection of papers and other resources for object detection and tracking using deep learning
- YOLO: Real-Time Object Detection
- YOLO: ImageNet Classification
- Video: YOLO Live
- Hackernoon: Understanding YOLO
- Medium: What do we learn from single shot object detectors (SSD, YOLOv3), FPN & Focal loss (RetinaNet)?
- Towards Data Science: Deep Learning for Object Detection: A Comprehensive Review (uma repetição, sob outra ótica, do que eu falei a acima e na próxima seção)
- Medium::(Como usar e quais versões)::Object detection with YOLO: implementations and how to use them
- Medium::YOLO v3 theory explained (Bom!)
- Medium::YOLO, YOLOv2 and YOLOv3: All You want to know (Bom!)
- Medium::Object Detection YOLO v1 , v2, v3
- Medium::YOLO — ‘You only look once’ for Object Detection explained
- Medium::Overview of the YOLO Object Detection Algorithm
- TowardsSataScience::What’s new in YOLO v3?
- TowardsSataScience::YOLO — You only look once, real time object detection explained
- TowardsSataScience::Review: YOLOv3 — You Only Look Once (Object Detection)
Usando YOLO com Keras
Muitas implementações de YOLO que encontramos por aí são baseadas em DNN (OpenCV) ou DLib (C++). Abaixo há algumas implementações de YOLO.V2 e YOLO.V3 construídas sobre Python e Keras:
- YOLO.V3:
- A Keras implementation of YOLOv3 (Tensorflow backend)
- Código do Artigo acima no Keras Model Zoo
- YOLO3 (Detection, Training, and Evaluation) (postado por Huynh Ngoc Anh/experiencor)
- YOLOv3 – Keras(TF backend) implementation of yolo v3 objects detection (postado por Larry Xiaochus)
- YOLO.V2:
- YAD2K: Yet Another Darknet 2 Keras
- YOLOv2 (and v3) in Keras and Applications: Easy training on custom dataset. Various backends (MobileNet and SqueezeNet)
- Medium::Quick implementation of Yolo V2 with Keras!
Retreinando YOLO para novos Objetos
- YOLO.V3:
- Medium::How to train YOLOv3 to detect custom objects, a tutorial on how to train cat and dog object using Yolo-v3
- hackernoon::Efficient Implementation of MobileNet and YOLO Object Detection Algorithms for Image Annotation
- TowardsDataScience::Training Yolo for Object Detection in PyTorch with Your Custom Dataset — The Simple Way por Chris Fotache
- YOLO.V2:
- YOLOv2 (and v3) in Keras and Applications: Easy training on custom dataset. Various backends (MobileNet and SqueezeNet)
- easy-yolo: Yolo (Real time object detection) model training tutorial with deep learning neural networks
- Medium::How to train YOLOv2 to detect custom objects (ubuntu 16.04) (Manivannan Murugavel usa os binários C++ de Darknet!)
- Nils Tijtgat: How to train YOLOv2 to detect custom objects

Você vai necessitar das ferramentas discutidas aqui: Deep Learning::Ensinando à Rede: Ferramentas de Anotação
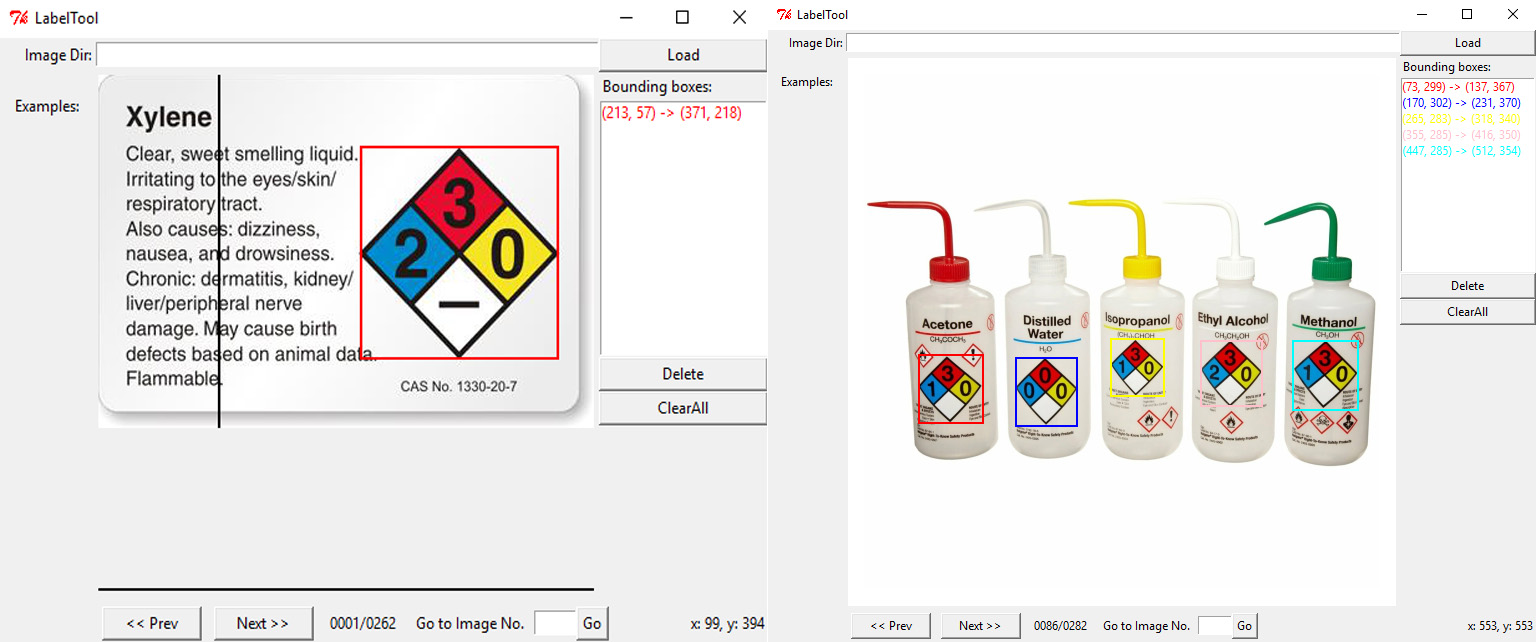
Usando YOLO com PyTorch
- TowardsDataScience::Object detection and tracking in PyTorch (com Jupyter)
- TowardsDataScience::Training Yolo for Object Detection in PyTorch with Your Custom Dataset — The Simple Way por Chris Fotache
- Paperspace::How to implement a YOLO (v3) object detector from scratch in PyTorch
- Implementing YOLO-V3 Using PyTorch
- KDNuggets::How to Implement a YOLO (v3) Object Detector from Scratch in PyTorch
- Github::A PyTorch implementation of a YOLO v3 Object Detector
- Github::A minimal PyTorch implementation of YOLOv3, with support for training, inference and evaluation
- Github::PyTorch YOLOv3 software developed by Ultralytics LLC
Usando YOLO com TensorFlow puro
Usando YOLO com JavaScript
- Towards Data Science::In-Browser object detection using YOLO and TensorFlow.js
- Hackernoon::TensorFlow.js — Real-Time Object Detection in 10 Lines of Code
SSD – Single Shot Detection
SSD, discretiza o espaço de bounding boxes de saída em um conjunto padronizado de bboxes de diferentes taxas de aspecto (aspect ratios) e os escala de acordo com a localização do mapa de características identificado.
SSD:
- Durante a predição, a rede gera scores para a presença de cada categoria de objeto em cada bbox padrão e produz ajustes para o bbox que nelhor se ajustar ao formato do objeto.
- Para isso, a rede combina predições geradas por múltilos mapas d ecaracterísticas com diferentes resoluções para naturalmente lidar com objetos de diferentes tamanhos.
- É um modelo simples se comparado a métodos que requerem a geração de propostas de objetos pois elimina completamente a geração de propostas e a subseqüente reamostragem de pixels ou características e encapsula todos os cálculos em uma única rede.
- É fácil de treinar por causa de sua simplicidade, sendo fácil de integrar em sistemas que necessitam de uma componente de detecção.
Experimentos realizados pelos autores em dataset como PASCAL VOC, MS COCO e ILSVRC datasets demonstraram que SSD possui acurácia comparável a métodos que utilizam propostas de objetos e é muito mais rápido, com a vantgem de prover uma infraestrutura unificada para treinamento e predição. Quando comparado a outros métodos como YOLO, SSD é muito mais curado mesmo usando imagens de enyrada de resolução menor.
Links:
- Artigo original: SSD: Single Shot MultiBox Detector – Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg
- Medium:: SSD object detection: Single Shot MultiBox Detector for real-time processing
- Medium::Understand Single Shot MultiBox Detector (SSD) and Implement It in Pytorch
- Towards Data Science::Understanding SSD MultiBox — Real-Time Object Detection In Deep Learning
Usando OpenCV Deep Learning Object Detection Library
- Medium::Exploring OpenCV’s Deep Learning Object Detection Library (exemplos com SSD/MobileNet e YOLOv2)
Redes de Dois Estágios com Focal Loss
- RetinaNet (2018!)
- Keras implementation of RetinaNet object detection
- Focal Loss for Dense Object Detection by Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He and Piotr Dollár
- Repositório Python: keras-retinanet 0.4.1
RetinaNet
Links
Detecção de Objetos Integrada à Segmentação Semântica
- Detectron – Detectron é o sistema da divisão de P&D em IA do Facebook que implementa algoritmos estado-da-arte para detecção de objetos, incluindo Mask R-CNN.
A versão atual é escrita em Python e baseia no framework Caffe. - Mask R-CNN – Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick (2018) – a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition.
- Usando a Tensorflow Object Detection API: Towards Data Science – Using Tensorflow Object Detection to do Pixel Wise Classification

Aplicações no Browser ou com JavaScript
- Hackernoon::TensorFlow.js — Real-Time Object Detection in 10 Lines of Code
- TensorFlow.js:: Real-Time Object Detection Demo
- TensorFlow.js:: Real-Time Object Detection Demo (Full Code)
- TensorFlow.js::Simple Object Detection (Desenhos Simples)
- GitHub::Simple Object Detection (Desenhos Simples)
- Medium::Building Realtime Object Detection WebApp with Tensorflow.js and Angular
Model Zoos em outros Frameworks
Como avaliar e validar a qualidade do seu modelo?
- Reconhecimento de Padrões::Avaliando, Validando e Testando o seu Modelo: Metodologias de Avaliação de Performance
Copyright © 2018 Aldo von Wangenheim/INCoD/Universidade Federal de Santa Catarina