“The definition of genius is taking the complex and making it simple.”― Albert Einstein
Para validar e testar o seu Modelo de Reconhecimento de Padrões ou Visão Computacional (Etapa IV em nosso gráfico de cruzamento de Domínios X Etapas na Visão Computacional), você vai necessitar de metodologias adequadas.
Esta página tem por objetivo apresentar e explicar Metodologias de Avaliação de Performance para Aprendizado de Máquina, Reconhecimento de Padrões e Visão Computacional. Estas metodologias foram originalmente desenvolvidas para avaliar métodos estatísticos, mas hoje têm aplicação em uma gama muito mais ampla de áreas.

Como entender a selva de métodos de avaliação?
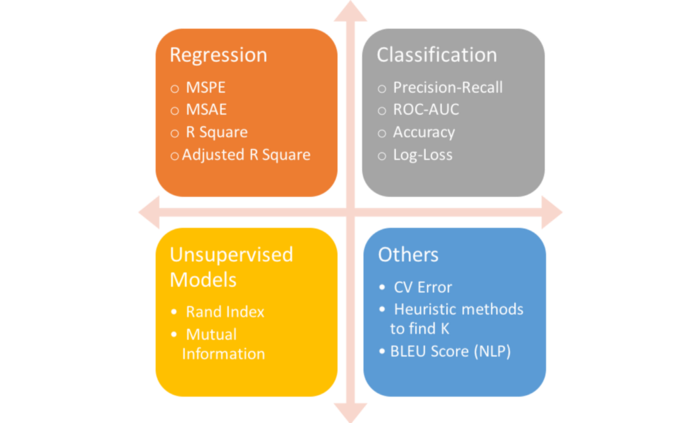
Contents
- 1 Conceitos Básicos
- 1.1 Modelos de Classificação
- 1.1.1 Verdadeiros positivos, verdadeiros negativos, Falsos positivos efalss negativos
- 1.1.2 Matriz de Confusão
- 1.1.3 Acurácia
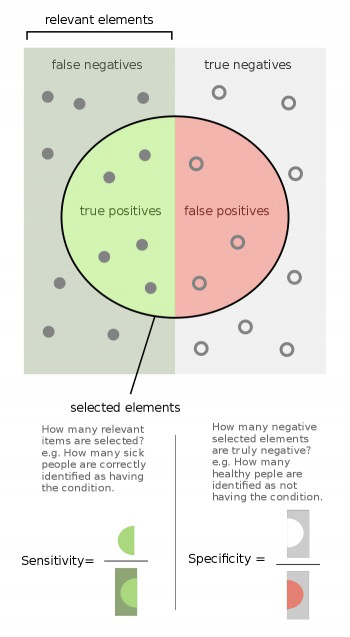
- 1.1.4 Sensibilidade (Recall) e Precisão
- 1.1.5 Especificidade
- 1.1.6 Escore F1
- 1.1.7 Curva AUC-ROC
- 1.1.8 Perda Logarítmica (Logarithmic Loss)
- 1.1.9 Acurácia Multiclasse Balanceada
- 1.1.10 O meu problema é multiclasse e desbalanceado. O que eu uso?
- 1.2 Modelos de Regressão
- 1.3 Modelos Não Supervisionados
- 1.1 Modelos de Classificação
- 2 Links Interessantes
Conceitos Básicos
Aqui nós vamos apresentar alguns conceitos básicos como Matriz de Confusão, Acurácia, Valor Preditivo, ROC-AUC, F1, etc.
Modelos de Classificação
Modelos de classificação simplesmente avaliam se o seu modelo de reconhecimento de padrões acertou ou errou a classificação: só há acertos de erros e, a partir daí, cria-se métricas de como levar em consideração estes acertos e erros.
Verdadeiros positivos, verdadeiros negativos, Falsos positivos efalss negativos
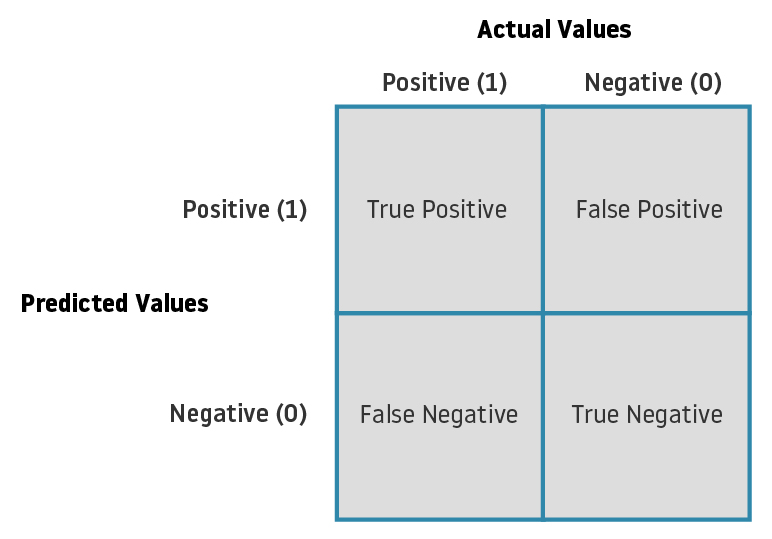
Matriz de Confusão
Acurácia
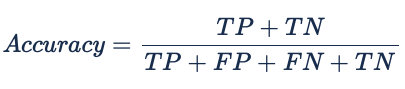
Sensibilidade (Recall) e Precisão
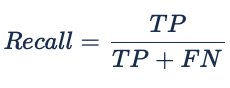
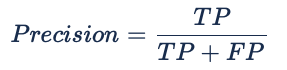
Especificidade
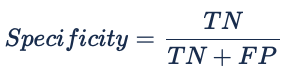
Escore F1

ou:
f1 = 2*precision*recall/(precision + recall) Referências:
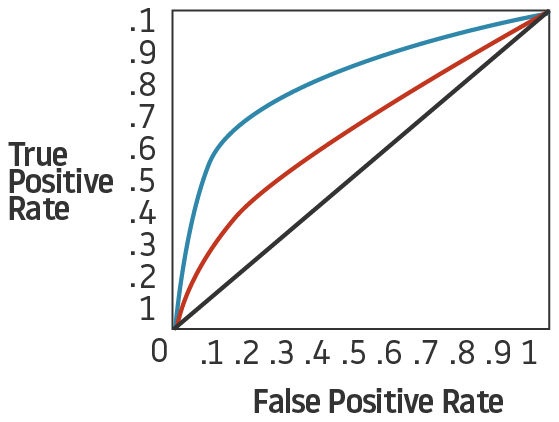
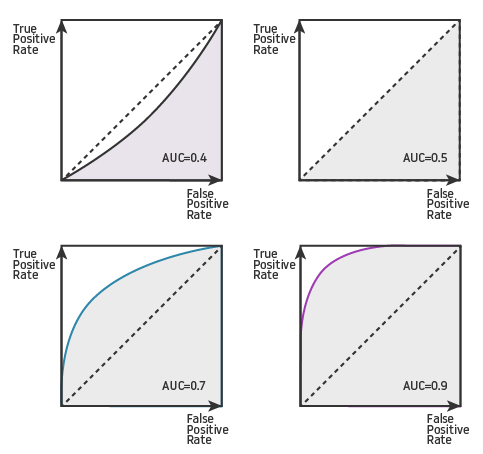
Curva AUC-ROC
Perda Logarítmica (Logarithmic Loss)

Onde:
- y_ij, indicates whether sample i belongs to class j or not
- p_ij, indicates the probability of sample i belonging to class j
Acurácia Multiclasse Balanceada
Observe a matriz de confusão abaixo (fonte: conjunto de validação (20%) gerado por nós a partir da ISIC 2019 Skin Cancer Challenge):
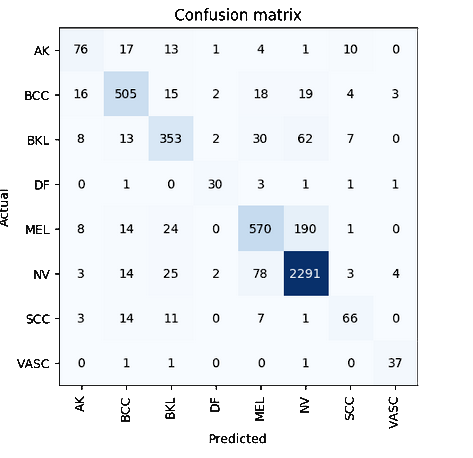
Observe que actual X predicted está representado diferentemente da matriz-exemplo acima.
Evidentemente a classe NV possui muito mais instâncias que as outras classes. Isso significa que, em uma mtrica como a acurácia da seção anterior, o nosso resultado vai ser desmesuradamente influenciado por esta classe. Uma performance muito boa com NV e péssim com as outras classes ainda assim vai resultar em uma acurácia boa, o que não reflete adequadamente a confiabilidade desse modelo.
Quando ocorrem distribuições desbalanceadas de padrões como a acima, optamos por balancear o cálculo da acurácia, ponderando-o pelo número de instâncias de cada classe.
b_acc = (sensitivity + specificity)/2O meu problema é multiclasse e desbalanceado. O que eu uso?
Modelos de Regressão
Modelos de regressão trabalham com valores contínuos e têm por objetivo servir para estimar o que seria a entrada de dados original que gerou o resultado que o seu modelo de reconhecimento depadrões está mostrando. Eles permitem não apenas prever a classe do dado de entrada, mas também prever o seu valor.
MAE
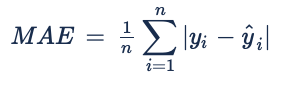
RMSE
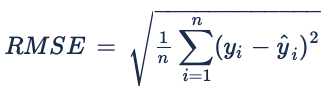
Modelos Não Supervisionados
O nome modelos não supervisionados, escolhido pela autora do desenho diagramático acima no início da página, baseada na ideia de que são clustering methods, na verdade engana: estes modelos de avaliação, como quaisquer outros, necessitam de alguma referência para que se possa determinar o que está certo e o que está errado.
Rand Index
Durante muito tempo, o modelo mais utilizado em visão computacional dentre estes modelos, foi o Rand Index. Ele é um modelo usado para avaliar a qualidade da segmentação gerada por algoritmos de segmentação por crescimento de regiões clássicos.
Este modelo usa um ou mais Ground Truths – GTs, normalmente gerados a mão por humanos, e compara o resultado de uma segmentação clássica por crescimento de regiões a estes GTs. Tipicamente os GTs são formados por bordas de regiões ou segmentos e o modelo é usado considerando-se essas bordas como limites de conjuntos e analisando-se o resultado das segmentações pertence ou não a esses conjuntos.
Um conjunto de dados público muito conhecido que usa este modelo de GT é o Berkeley Dataset (https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/bsds/). Neste conjunto de dados, a universidade de Berkeley usou alunos do curso de Artes para avaliar imagens e marcar a mão o que consideravam que seria o limite de cada objeto na imagem.

Imagem com limites definidos por um dos usuários humanos sendo mostrados em verde
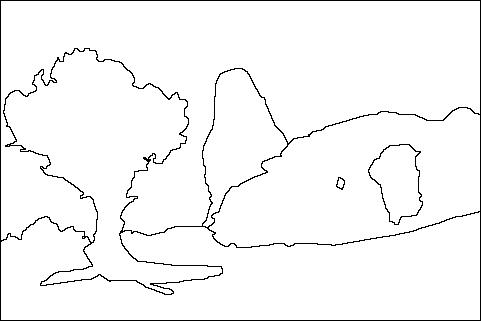
Apenas os limites de cada objeto identificado pelo humano na imagem
O Rand index não é mais um modelo atual, por isso não vamos entrar em detalhes. Hoje utiliza-se um modelo muito mais simples e mais fácil de calcular, mas que possui expressividade equivalente: o modelo Intersection over Union (IoU).
Abaixo, algumas referências interessantes, dentre o artigo original do Rand Index e também alguns artigos antigos nossos, onde utilizamos este modelo para avaliação de segmentação por crescimento de regiões.
Links Interessantes:
- W. M. Rand (1971). “Objective criteria for the evaluation of clustering methods”. Journal of the American Statistical Association. American Statistical Association. 66 (336): 846–850. arXiv:1704.01036. doi:10.2307/2284239. JSTOR 2284239
- Exemplo de cálculo do Rand Index em R com base em dados numéricos e não de imagem: https://davetang.org/muse/2017/09/21/the-rand-index/
- Função do Rand Index no pacote Python SciKit: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.adjusted_rand_score.html
- CARVALHO, L. E. ; MANTELLI NETO, S. L. ; SOBIERANSKI, A. C. ; COMUNELLO, E. ; VON WANGENHEIM, ALDO . Improving Graph-Based Image Segmentation Using Nonlinear Color Similarity Metrics. International Journal of Image and Graphics, v. 15, p. 1550018, 2015.
- CARVALHO, L. E. ; MANTELLI NETO, S. L. ; VON WANGENHEIM, ALDO ; SOBIERANSKI, A. C. ; COSER, L. ; COMUNELLO, E. . Hybrid Color Segmentation Method Using a Customized Nonlinear Similarity Function. International Journal of Image and Graphics, v. 14, p. 1450005-145025, 2014.
- Sobieranski, Antonio Carlos ; COMUNELLO, E. ; VON WANGENHEIM, ALDO . Learning a nonlinear distance metric for supervised region-merging image segmentation. Computer Vision and Image Understanding (Print), v. 115, p. 127-139, 2011.
- SOBIERANSKI, A. C. ; ABDALA, D. D. ; COMUNELLO, E. ; VON WANGENHEIM, ALDO . Learning a Color Distance Metric for Region-Based Image Segmentation. Pattern Recognition Letters, p. 1-15, 2009.
- VON WANGENHEIM, ALDO; BERTOLDI, R. F. ; ABDALA, D. D. ; SOBIERANSKI, A. C. ; COSER, L. ; JIANG, X. ; RICHTER, Michael M. ; Priese, L. ; Schmitt, F. . Color image segmentation using an enhanced Gradient Network Method. Pattern Recognition Letters, v. 30, p. 1404-1412, 2009.
Intersection over Union (IoU)
O Jaccard index, também conhecido como Intersecção sobre União ou coeficiente de similaridade de Jaccard, é uma estatística para estimar a similaridade entre dois conjuntos de amostras. Mede a similaridade entre dois conjuntos finitos e é dado pela seguinte fórmula:
Este modelo transformou-se no modelo padrão de avaliação de qualidade em segmentação semântica com redes neurais convolucionais, por isso nós vamos focar nele. Ele também é um modelo preferencialmente utilizado para avaliação de qualidade na detecção de objetos com redes neurais convolucionais.
Pictoricamente, a ideia geral e a da figura adiante:
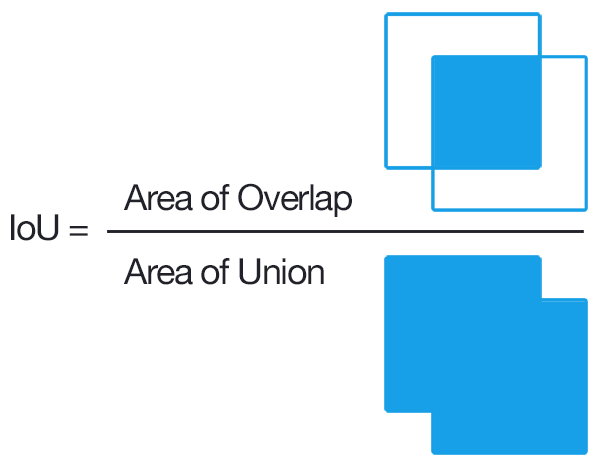
a ideia básica é a de que a, quanto maior for a superposição entre o GT e o objeto identificado/previsto por um método de aprendizado de máquina, tanto melhor será o valor de IoU:
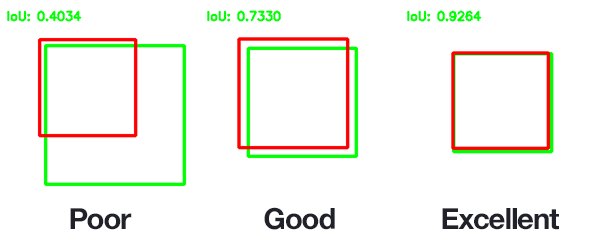
IoU na detecção de objetos
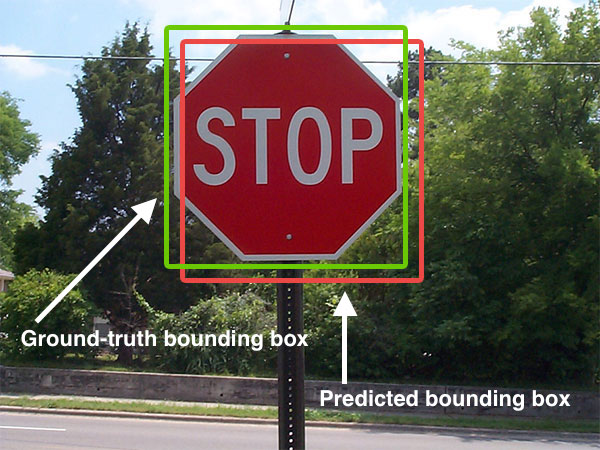

IoU na segmentação semântica
Na figura abaixo temos duas regiões: um GT e uma predição.

Na próxima figura vemos, à esquerda a intersecção, a direita a união:

Links Interessantes
- Apresentação de Nathalie Japkowicz na ICMLA 2011 com uma excelente visão geral. Comece por aqui: Overview of Performance Measures
- The slides of the tutorial presentation given at Canadian AI 2016, May 31, 9:00am – 12:00pm, Victoria, BC are downloadable here (2.33 MB, 87 Slides)
- Medium::Performance Metrics: When to Use What por Utkarsh Dixit
- Medium::Choosing the Right Metric for Evaluating Machine Learning Models — Part 1 por Alvira Swalin
- Medium::Choosing the Right Metric for Evaluating Machine Learning Models — Part 2 por Alvira Swalin
- TowardsDataScience::Various ways to evaluate a machine learning model’s performance – Because finding accuracy is not enough por Kartik Nighania
- TowardsDataScience::Metrics to Evaluate your Machine Learning Algorithm por Aditya Mishra
- Artigo::Peter Flach. Performance Evaluation in Machine Learning:The Good, The Bad, The Ugly and The Way Forward, AAAI 2019
- Datascience::Mine is better: Metrics for evaluating your (and others) Machine Learning models por Pablo Hernandez
- TowardsDataScience::Simplifying the ROC and AUC metrics – Taking the confusion out of classification metrics por Parul Pandey (MUITO bom!)
- TowardsDataScience::Understanding AUC – ROC Curve por Sarang Narkhede
- TowardsDataScience::Understanding Confusion Matrix por Sarang Narkhede