Contents
- 1 Padrões e Métricas de Distância entre Padrões
- 2 Tesselação: Trangulação de Delaunay e o Diagrama de Voronoi
- 3 Exercícios
- 4 Links & Material Adicional
Padrões e Métricas de Distância entre Padrões
O que são padrões?
Significado em matemática e computação:
A pattern, from the French patron, is a type of theme of recurring events or objects, sometimes referred to as elements of a set of objects.
Exemplos de Padrões Sintéticos
O conceito de padrão não é difícil de entender de forma intuitiva. O mais simples de se imaginar são padrões visuais. Pense em padrões de estampas de tecidos. A costureira do seu bairro, se você perguntar, vai ter uma noção intuitiva muito correta de o que é um padrão. Observe as imagens abaixo e diga o que você enxerga de comum:
 |
 |
 |
 |
Padrões na Natureza
Muitos processos naturais geram padrões fáceis de idetnificar visualmente. Processos de crescimento em vegetais e animais são um exemplo bastante característico, tanto envolvendo uma comunidade de espécimes diferentes (primeira linha da tabela) quanto em estruturas de um componentes de um espécime específico (duas linhas inferiores da tabela):
 |
 |
 |
 |
 |
 |
Padrões Temporais em Processos Biológicos
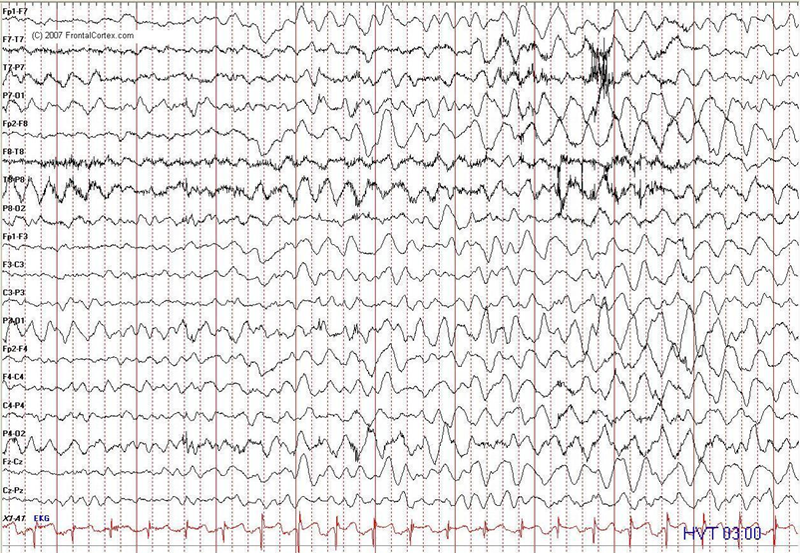
Um padrão não necessita existir em uma estrutura estática, ele pode ser identificado ao longo do tempo, em um processo. Muitos processos biológicos geram padrões identificáveis, como por exemplo as ondas cerebrais humanas em um eletroencéfalograma:
Outros Exemplos de Padrões produzidos por Processos
Não só processos biológicos, mas muitos outros processo s, tanto naturais quanto artificiais, podem produzir padrões. Veja abaixo dois exemplos: (a) marcas de pneus na areia e (b) estrutura de cristais em um processo de congelamento.
 |
 |
Construindo e Reconhecendo Padrões
Como montamos um padrão?
Geralmente dados sob a forma de pares atributo-valor
–atributo é definido pela posição do valor em um vetor de dados,
–ex.: (1 2 4 11.01 1), representando: (num_imóveis, num_carros, num_filhos, idade_media_filhos, bom/mau pagador)
Dados numéricos ou representações numéricas de dados simbólicos
–ex: 1=fumante, 2=não fumante, 3=fumante eventual.
Os relacionamentos entre os dados são desconhecidos.
–Se os padrões são pré-classificados em classes, essas geralmente são resultado da experiência de usuários humanos no domínio de aplicação.
Objetivo quase sempre será o de reconhecer padrões
–classificá-los, porém sem gerar explicações complexas sobre o porquê desta classificação.
Como reconhecemos padrões ?
- Classificação: Se já sabemos quantas categorias possuímos e temos exemplos de instâncias de cada categoria: queremos criar um classificador.
- Os pares atributo-valor em dados para um classificador possuem um atributo especial que é a classe ou categoria à qual aquele padrão específico pertence.
- Um classificador vai utilizar nossos exemplos para classificar novos dados.
- Agrupamento: Se temos dados mas não sabemos como se organizam, temos de minerá-los: queremos criar um agrupador.
- O resultado desse agrupamento, adequadamente representado, pode ser utilizado para classificações futuras.
Como se Aprendem Padrões em RP?
Padrões podem ser aprendidos de duas formas:
- Através do Aprendizado Supervisionado ou
- Através do Aprendizado Não-Supervisionado
Quando usamos qual?
- Problemas de Classificação: usamos Aprendizado Supervisionado
- Existe a figura do professor, que:
- apresenta os exemplos a serem aprendidos e
- controla a avaliação da qualidade do aprendizado.
- Conhecemos o domínio de aplicação bem o suficiente e sabemos de antemão quais as classes de padrões que vão existir.
- O objetivo do aprendizado é criar um classificador capaz de replicar este conhecimento e, eventualmente, refiná-lo:
- Possuímos um conjunto de padrões pré-classificados que podemos utilizar como ponto de partida.
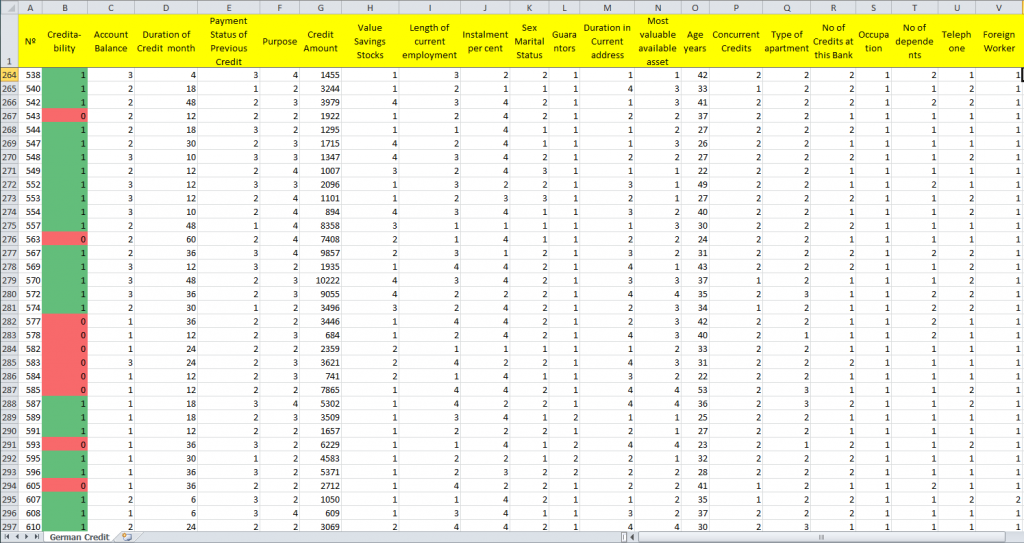
- Ex.: Um banco possue uma coleção de descrições de clientes de empréstimos que foram atendidos nos últimos anos e classificados como bom-pagador e mau-pagador. O objetivo é integrar este conhecimento em um sistema através de aprendizado de forma a futuramente poder utilizá-lo na classificação de novos clientes procurando empréstimo.
- Uma base de dados pública de crédito de um banco alemão é um exemplo típco usado em testes de métodos supervisionados de RP. Nesse exemplo, mostrado parcialmente na figura abaixo, há dois campos na lista de pares atributo-valor que não são dados que serão usados na métrica de distância:
- Existe a figura do professor, que:
- Problemas de Agrupamento: usamos Aprendizado Não-Supervisionado
- Não sabemos ainda em que grupos os nosso dados se dividem. As estruturas existentes nos exemplos a serem aprendidos devem ser descobertas pelo aprendizado:
- Padrões são aprendidos de forma indutiva;
- Controle da qualidade do resultado é feito por meio de análise estatística dos agrupamentos resultantes ou por comparação a posteriori com um conjunto independente de agrupamentos pré-classificados.
- Uma outra base de dados pública, a base de classificação das flores do gênero Iris é um exemplo comumente utilizado em RP para teste de métodos de agrupamento.
- Iris sp é uma flor dividida em poucas espécies e essas espécies podem ser diferenciadas com abes em apenas quatro variáveis: Comp. Sépalas, Larg. Sépalas, Comp. Pétalas e Larg. Pétalas.

Exemplos de Iris do jardim do Professor
- Uma planilha com dados de Iris (nesse caso o Fisher (1936) iris data) pode ser agrupada com diferentes métodos e é fácil de ser validada. As observações da planilha abaixo estão pré-categorizadas e a essa classificação pode ser usada para uma validação a posteriorir:
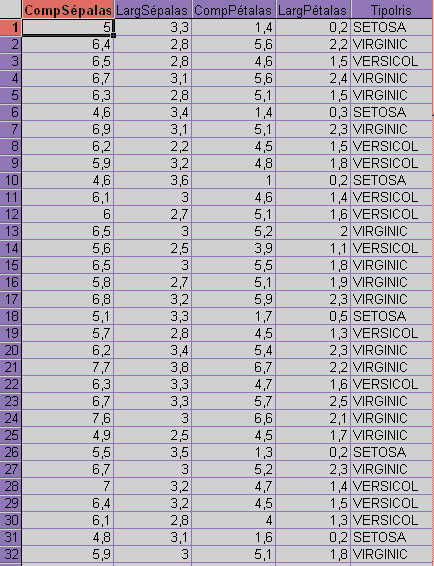
Dados do gênero Iris
- No exemplo da figura abaixo temos as três espécies do gênero Iris agrupadas por apenas duas variáveis:
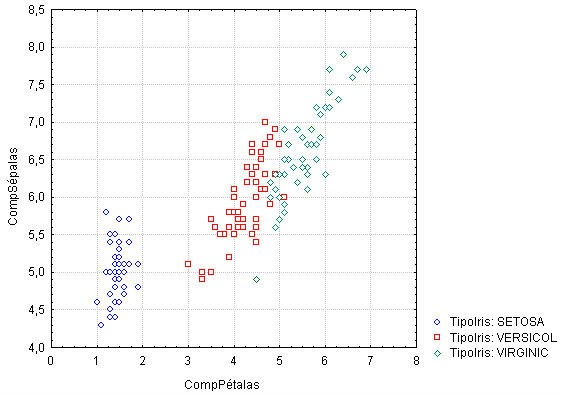
Iris agrupadas por apenas duas variáveis
- Iris sp é uma flor dividida em poucas espécies e essas espécies podem ser diferenciadas com abes em apenas quatro variáveis: Comp. Sépalas, Larg. Sépalas, Comp. Pétalas e Larg. Pétalas.
- Não sabemos ainda em que grupos os nosso dados se dividem. As estruturas existentes nos exemplos a serem aprendidos devem ser descobertas pelo aprendizado:
Existem mecanismos tanto de aprendizado supervisionado quanto de aprendizado não supervisionado nos diferentes grupos de técnicas de RP que vamos ver: Aprendizado de Máquina, Redes Neurais e Estatística Exploratória.
O que é Indução?
Indução ou Raciocínio Indutivo é um conceito que aparecerá de forma recorrente quando estudarmos Reconhecimento de Padrões ou, mais tarde, quando você estudar Mineração de Dados ou assuntos relacionados.
Indução pode ser definida, de forma geral, como o processo de raciocínio utilizado para se chegar a um resultado a partir de elementos previamente observados ou indicativos para tal conclusão.
Indução é um processo de raciocínio natural no ser humano e pode ser observado mesmo nas crianças pequenas: um bebê que mal engatinha já induz a lei da gravidade levantando e soltando repetidamente um objeto e olhando-o cair. A indução é o primeiro passo na descoberta de novos fenômenos naturais. Observa-se que sempre que determinada situação ocorre, determinado fenômeno é observável (simultaneidade). A observação induz à conclusão de que o fenômeno está associado à situação, sem no entanto explicar a natureza desta associação.
O aprendizado indutivo é também chamado de aprendizado sintético: sintetizamos categorias a partir da observação de fenômenos. Permitimos que fatos observados induzam a síntese de conclusões abstratas sobre a natureza do observado. A ideia básica é a de que uma conclusão C é a descrição, abstrata, geral de fenômeno que obedece a certas leis, sintetizadas através de C.
Ao contrário do que acontece na dedução, não há prova absoluta na indução. Fenômenos inferidos por indução podem estar errados.
Classe ou Categoria?
Para podermos falar adequadamente de conceitos envolvidos no Reconhecimento de Padrões, temos de primeiramente definir o nosso vocabulário. É intuitivo que padrões se permitem agrupar ou classificar em grupos ou conjuntos similares, onde, dentro de um contexto bem definido (ex.: a área de aplicação do nosso software de reconhecimento de padrões -> classes de padrões de crescimento em plantações de soja), padrões de um mesmo agrupamento possuem semântica similar (ex.: bom_crescimento, crescimento_lento, falta_adubo, praga).
Devemos chamar estes agrupamentos de classe ou categoria?
No linguajar coloquial os termos tipo, classe e categoria possuem significado equivalente. Reconhecimento de Padrões, porém, é uma área da Matemática. É necessário usar uma definição mais formal? Se olharmos para as definições dos termos classe e categoria linkadas nessa página, vamos ver que cada um desses termos possui muitas definições, algumas delas no campo da matemática e da filosofia (e que poderiam ser-nos úteis) e outras do campo da ciência política ou da literatura que, com toda certeza, não possuem nenhuma utilidade para nós. Mas, mesmo quando olhamos definições dentro de uma mesma área, essas definições são confusas (ex.: filosofia): o que têm as categorias Kantianas a ver com as categorias Estóicas?
Diferentes definições para Classe e Categoria
A título de exercício, abra as listas de definições de classe e categoria na Wikipedia (links acima nesta página) estude brevemente as diferentes definições.
O que muitas vezes se tem usado em RP é que, quando um agrupamento é resultado de decisões ou de um processo de projeto ou planejamento, então ele é uma classe e quando um agrupamento é o resultado de um processo de descoberta, mineração ou organização natural, ou seja, o resultado de um processo de indução, ele é uma categoria.
Isso significaria que, quando estamos trabalhando com cum classificador e temos padrões pré-classificados ou associados a agrupamentos definidos arbitrariamente por humanos, então temos classes. Por outro lado, quando estamos trabalhando com agrupadores e estamos explorando conjuntos de dados com padrões de agrupamentos a priori desconhecidos, então os grupos resultantes são categorias. O processo de produção de categorias a partir de observação (já abordado nas obras de Platão e Aristóteles) é denominado categorização.
Essa diferenciação, no entanto, não é compartilhada por todos os autores. Na literatura da Análise de Agrupamentos, um processo definitivamente indutivo, por exemplo, é comum encontrar-se passsagens onde os agrupamentos são referidos como classes.
No correr desta disciplina nós vamos ser pragmáticos e tratar os termos classe e categoria como sinônimos e usar o termo classe por ser de uso mais comum
Medidas de distância entre padrões: a distância de Hamming, Nearest Neighbour, kNN e Outras
Distância de Hamming:
- Originalmente criada para vetores binários. Media distância entre vetores contando o número de bits diferentes (mismatch count).
- Mais útil em RP: Hamming extendido ou Hamming+. Soma das diferenças escalares absolutas entre os valores correspondentes de dois vetores. Cálculo extremamente rápido.
- DistHamming( (10, 2000, 20, 4, 0, 0, 0), (2, 3000, 40, 5, 100, 4, 1) ) = ( (10 -8)+(3000 -2000)+(40 -20)+(5 -4)+(100 -0)+(4 -0)+(1 -0) ) = (8 + 1000 + 20 + 1 + 100 + 4 + 1) = 1134
Distância Euclidiana:
- Extensão n-dimensional da regra básica da trigonometria: Teorema de Pitágoras.
- Provê a real distância entre dois pontos em um espaço n-dimensional qualquer.
- Nem sempre é melhor que Hamming, pois coloca todas as variáveis na mesma escala.
- Cálculo bastante demorado para dimensões elevadas.
- Variáveis sobre escalas muito diferentes devem ser normalizadas para [0,1].
Exemplos de Problemas de Classificação
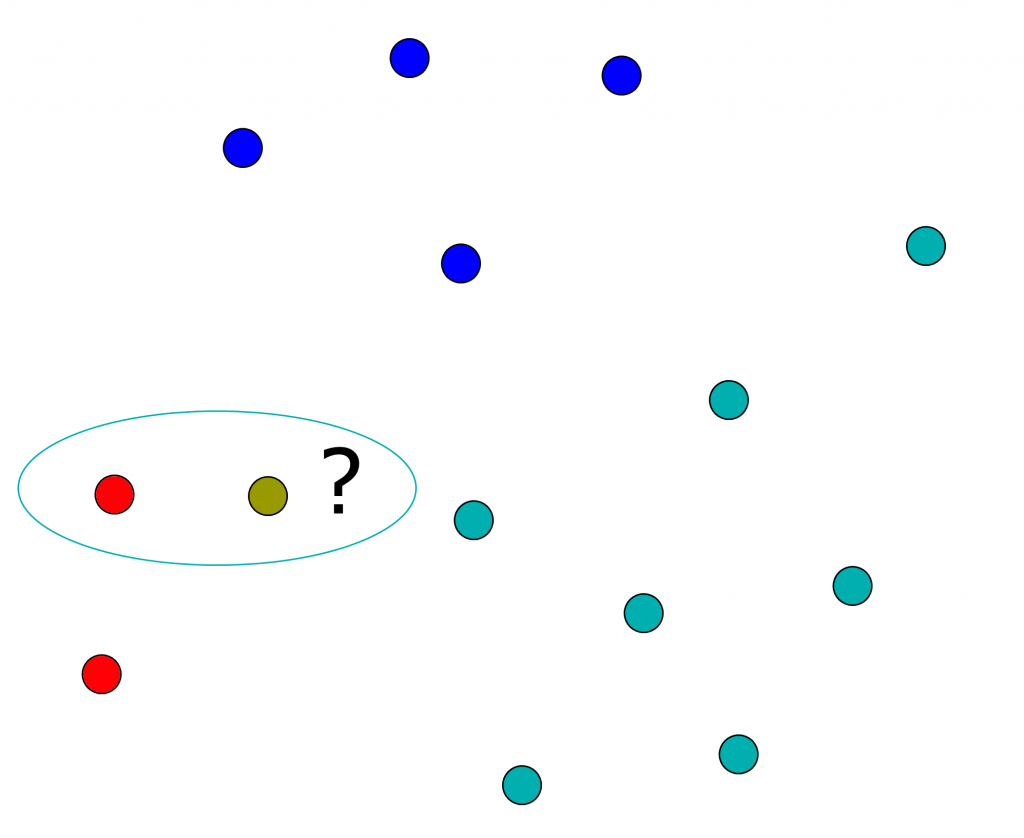
Imagine os conjuntos de dados abaixo. Quero classificar o dado verde-oliva. Se eu aplicar a distância euclidiana, vou classificá-lo como vermelho, que é a classe do elemento mais próximo:
Suponha agora que eu tenha uma situação mais complexa: O elemento verde-oliva ainda não classificado está próximo da classe azul, mas envolvido pela classe ciano. Qual será a sua classificação?
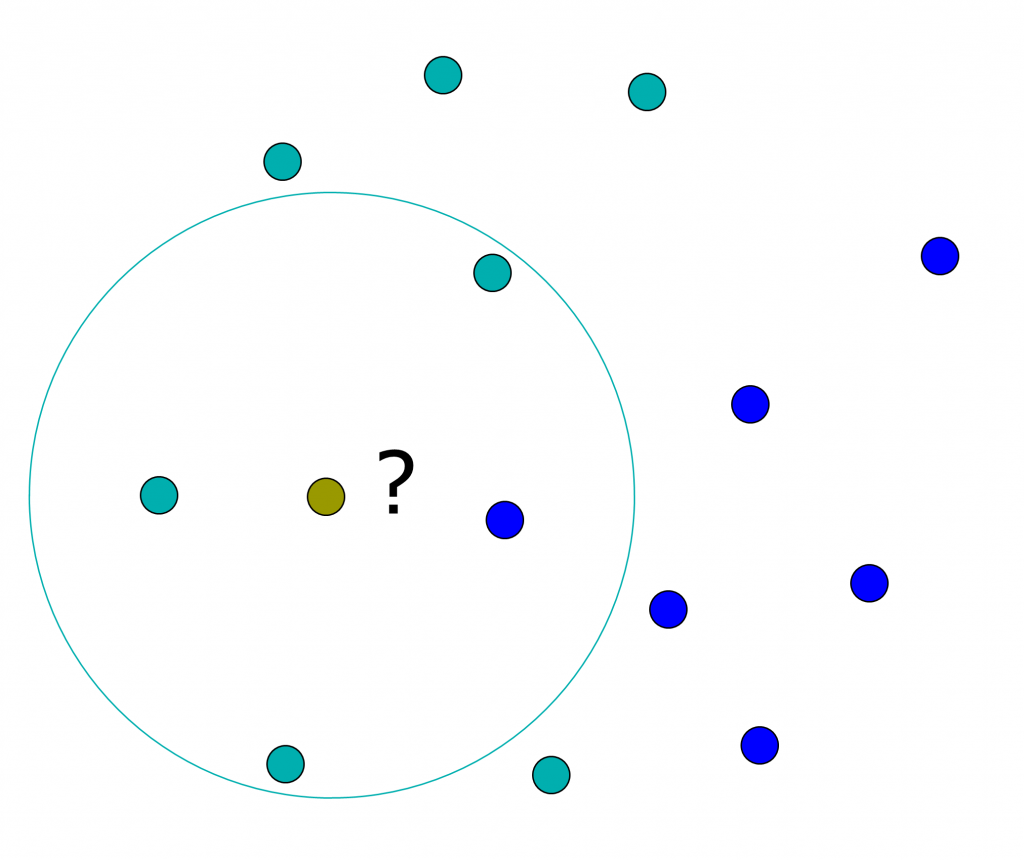
Nesse caso é mais interessante utilizar uma votação e ouvir a voz da maioria: pegamos os vizinhos dentro de um círculo ao redor de verde-oliva e vemos qual é a classe mais comum. Essa, assumimos, será a classe mais provavel de verde-oliva. Esse método é denominado k-Nearest Neighbour ou kNN:
- Tolerante a ruído: kNN utiliza um critério de votação: olho os k padrões mais próximos ao meu novo padrão.
- Classifico o padrão com a classe mais freqüente na lista de k padrões encontrada.
- A k-lista é mais fácil de implementar do que um raio, como no desenho acima, além de independer da dispersão dos dados.
- Desvantagem: k é um valor arbitrário que depende da natureza do problema e da qualidade dos dados que você possui (quanto maior o ruído, melhor fica um k maior) tem de ser determinado experimentalmente para cada conjunto de dados/problema a atacar.
- Um k muito grande me relação ao tamanho de seu conjunto de dados, por outro lado, vai produzir resultados sem sentido.
Tesselação: Trangulação de Delaunay e o Diagrama de Voronoi
Uma outra forma de gerarmos um classificador para padrões é a de dividirmos o espaço de dados em regiões através de algum método geométrico. Cada região representa então uma categoria ou classe. Classificamos padrões simplesmente olhando em que região caem. Chamamos a este conjunto de técnicas tesselação. A forma mais tradicional de tesselação é o Diagrama de Voronoi.
O que é um Diagrama de Voronoi?
O Diagrama de Voronoi foi inventado para resolver um problema simples: Como dividir uma cidade em áreas irregulares de forma a que a área coberta por um carteiro vinculado a uma determinada agência de correio seja otimizada?

Diagrama de Voronoi

G. F. Voronoi
G. F. Voronoi, em sua tese de outorado entitulada Ob odnom obobshchenii algorifma nepreryvnykh drobei (Isto é russo para Sobre uma generalização do algoritmo de quebra de cadeias. A transliteração do cirílico é de http://www.algebra.at/voron_d.htm), publicada em Russo em Varsóvia, Polônia, em 1896, desenvolveu um método onde, com base em uma triangulação préexistente de pontos que representam os centros de alguma coisa (no caso da primeira aplicação, agências de correio), se determina qual a área de influência de cada um destes centros em função da posição dos outros centros, delimitando de forma geométrica cada área de influência.
O diagrama de Voronoi é um método que tem extrema utilidade em reconhecimento de padrões para delimitar as áreas de categorias ou classes em uma representação geométrica de suas distribuições.

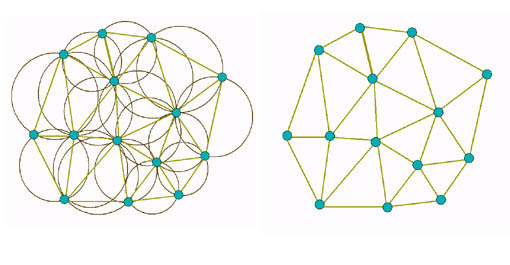
Triangulação de Delaunay
Chamamos estes “centros” de centróides. Se nós temos um conjunto de padrões constituído de um elemento típico para cada categoria que queremos representar (protótipo), podemos nos utilizar do diagrama de Voronoi para determinar a extensão de cada uma das categorias, simplesmente utilizando cada um dos protótipos como um centróide e gerando um diagrama de Voronoi sobre estes.
Para podermos gerar um diagrama de Voronoi partimos do conjunto de protótipos e geramos primeiramente uma triangulação. Para isto utilizamos o método da Triangulação de Delaunay, que veremos em detalhe adiante. Na figura acima, a triangulação está em vermelho.
Realizada a triangulação, geramos as linhas que formarão as fronteiras das células do diagrama de Voronoi. Estas fronteiras são geradas por linhas perpendiculares ao ponto médio de cada aresta da triangulação produzida anteriormente. As intersecções destas perpendiculares formam os vértices das células do diagrama de Voronoi. Os segmentos de reta da perpendicular que se extendem para além de sua primeira intersecção com outra perpendicular nos dois sentidos são descartados.
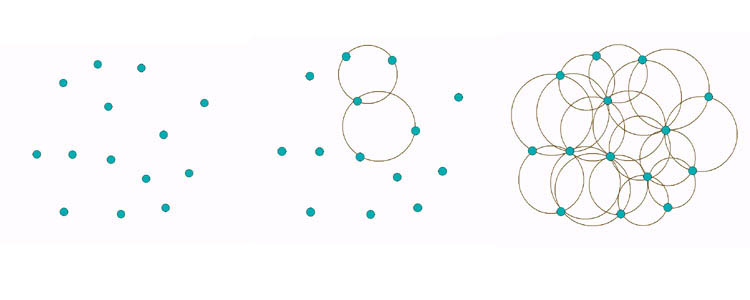
Na figura abaixo vemos em (a) uma triangulação inicial, em (b) o diagrama de Voronoi resultante e em (c) ambos sobrepostos.

Triangulação e Diagrama de Voronoi
Passos para a geração de um Diagrama de Voronoi
O algoritmo que descreveremos a aseguir é uma descrição de alto nível dos passos necessários para a geração de um diagrama de Voronoi para uma distribuição qualquer de dados sobre um plano. O método pressupõe que a distribuição de dados é bidimensional, sendo um caso particular do modelo geral. Se desejarmso mapear uma distribuição de dados de dimensão maior ou igual a 3 temos de utilizar planos e não segmentos de reta como fornteiras e cada elemento da triangulação será representado por um volume com n+1 faces, onde n é a dimensionalidade dos dados. Assim, por exemplo, paar representar dados em 3D através de um diagrama de Voronoi teremos de utilizar tetraedros (4 faces) como estrutura de triangulação.
Passo 1: Determinação dos pontos para os triangulos (Triangulação de Delaunay)
Tome sua distribuição de dados e encontre todos os triângulos definidos por três pontos da distribuição, de tal forma que um círculo passando por estes três pontos não inclua nenhum outro ponto.
Passo 1
Passo 2: Determinação dos triangulos (Triangulação de Delaunay)
Para cada conjunto de três pontos satisfazendo a condição de Delaunay encontrado, gere um triângulo.
Passo 2
Passo 3: Determinação das células (Diagrama de Voronoi)
P.3.1. Determine o ponto médio de cada um adas arestas do conjunto de triângulos gerado anteriormente. Considere cada aresta apenas uma vez.
P.3.2. Gere uma linha perpendicular a cada uma das arestas.
P.3.3. Determine as duas intersecções mais próximas de cada aresta com duas outras arestas. Um intersecção para cada lado. Ignore os segmentos de reta que seguem para além das intersecções.
P.3.4. Forme as células do diagrama com os polgonos formados por segmentos adjacentes. Ciclos geram células internas, polígonos abertos células externas.
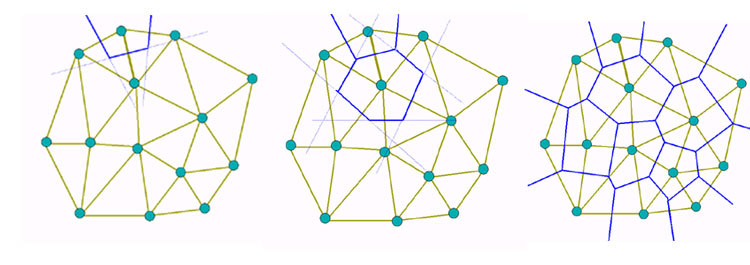
Passo 3
Exercícios
Alguns problemas clássicos: Dados em Espiral
Os conjuntos de dados em espiral podem ser utilizados para testes de performance em algoritmos de classificação de dados pois podem ser gerados automaticamente com variados graus de detalhes e ruído.
A espiral simples
Neste caso temos dados distribuídos em espiral em 2D. Cada ponto representa o protótipo de um acategoria ou classe. A tarefa de reconhecimento de padrões é classificá-los adequadamente, de forma a associar outros dados aleatórios a uma das classes existente na espiral.

Espiral Simples
A figura ao lado mostra a linha divisora da espiral que deve obrigatoriamente dividir as categorias das diferentes voltas do braço da espiral e mostra também algumas células de um diagrama de Voronoi hipotético gerado sobre a espiral. Você pode gerar uma espiral simples através de um algoritmo operando em coordenadas polares com passo constante e raio reduzindo-se linearmente.
A espiral dupla
As espirais múltiplas consituem um problema diferente da espiral simples. Em uma espiral múltipla, cada braço da espiral representa uma categoria ou classe. Cada classe é representada por muitos pontos, que são organizados sob forma de espiral. A tarefa aqui é classificar um ponto aleatório como pertencente a uma determinada classe, representada através de um braço da espiral.

Espiral Dupla
A figura acima mostra uma espiral de dois braços, onde um braço representa a classe azul e outro a classe vermelho. Cada classe é representada por um conjunto de pontos, organizados em espiral, de tal forma que os dois conjuntos de dados não são linearmente separáveis. A grande maioria dos algoritmos de classificação, inclusive redes neurais baseadas no perceptron simples (vide Minsky & Papert, Perceptrons, 1968), falha na tentativa de gerar um classificador capaz de separar estas duas classes.
Uma solução para evitar o uso de um enfoque não-linear para gerar um classificador para este conjunto de dados (como por exemplo uma rede neural bastante grande baseada em preceptrons mas utilizando o algoritmo Backpropagation de Rummelhart e McLelland) é gerar-se um classificador parcialmente linear (piecewise linear). Isto pode ser obtido, por exemplo através de comparação através de Nearest Neighbour com todos os dados da espiral. Nearest Neighbour é um classificador linear, mas se o usamos passo a passo com todos os elementos da espiral vamos descobrir uma classificação ótima para um dado aleatório. Outra opção (que no fundo é bastante similar nas suas bases) é considerar cada elemtno dos dois conjuntos de dados como um centroide e gerar-se um diagrama de Voronoi para a espiral dupla. Depois classifica-se cada uma das células como pertencendo à categoria vermelha ou azul, de acordo com a categoria de seu centroide.

Espiral Dupla SEN3
A figura acima mostra as duas superfícies de decisão de uma espiral de dois braços aprendido através de um modelo de rede neural denominado SEN3 (Self-Editing Nearest Neighbor Net – Rahmel & v.Wangenheim, 1994) com base em um conjunto de dados de uma espiral de dois braços contendo ruído. Observe que a geração das duas superfícies de decisão nã é perfeita. A rede SEN3 é inspirada no modelo de Kohonen e utiliza Nearest Neighbour como parte de sua regra de aprendizado.

Esfera – Diagrama de Voronoi
A figura acima mostra um Diagrama de Voronoi gerado para um conjunto de dados em espiral situados sobre a superfície de uma esfera.
Links & Material Adicional
Frameworks & APIs
Python
- Deep Learning: Veja nosso material de Deep Learning aqui.
- Visão Computacional::Ferramentas – Python e OpenCV
- Medium::Scikit-Learn: A silver bullet for basic machine learning
- scikit-learn::Machine Learning in Python
- Medium::Building a k-Nearest-Neighbors (k-NN) Model with Scikit-learn
R
- Datacamp::Machine Learning in R for beginners
- Laurent Gatto::An Introduction to Machine Learning with R
- Kaggle::Cam Nugent – Introduction to machine learning in R