Página para ajudar você a gerir com maestria o zoológico de conceitos e modelos em DL Obs.: Algumas coisas poddem estar em Inglês porque o texto está ainda sendo adaptado. As fontes estão citadas ao final...


Contents
- 1 Conceitos
- 1.1 Arquiteturas de Redes
- 1.1.1 Redes neurais convolucionais (Convolutional neural networks, CNNs ou deep convolutional neural networks, DCNNs)
- 1.1.2 Redes deconvolucionais (Deconvolutional networks, DNs, ou inverse graphics networks, IGNs)
- 1.1.3 Redes convolucionais gráficas inversas profundas (Deep convolutional inverse graphics networks, DCIGNs)
- 1.1.4 Autocodificadores variacionais (Variational autoencoders, VAEs)
- 1.1.5 Redes gerativas adversárias (Generative adversarial networks, GANs)
- 1.1.6 Redes neurais de transferência de estilo profundo (NST – Neural Style Transfer)
- 1.1.7 Redes residuais profundas (Deep residual networks, DRNs)
- 1.1.8 Redes totalmente convolucionais (Fully Convolutional Network, FCN)
- 1.1 Arquiteturas de Redes
- 2 Elementos Arquiteturais, Funcionais e de Análise
- 2.1 Análise de Resultados e Métricas de Performance
- 2.2 Elementos Funcionais
- 2.3 Elementos Estruturais
- 2.3.1 Convolução, camada convolucional (Convolution, convolutional layer)
- 2.3.2 Camadas convolucionais com kernels 1X1
- 2.3.3 Camada convolucional multicanal (Multi-channel convolutional layer)
- 2.3.4 Enchimento (Padding)
- 2.3.5 Passada ou marcha (Stride)
- 2.3.6 Conjugação máxima (Maximum pooling, max pooling)
- 2.3.7 Evanescimento ou fuga de gradientes e módulos residuais (gradient vanishing and residual modules)
- 2.3.8 Desconsideração de neurônios (Drop-Out, dropout)
- 2.3.9 Desconsideração de conexões (Drop-Connect, dropconnect)
- 3 Modelos
- 3.0.1 AlexNet
- 3.0.2 VGGNet
- 3.0.3 ResNet
- 3.0.4 GoogLeNet/Inception (ou Inception V1)
- 3.0.5 Inception V3
- 3.0.6 Redes convolucionais baseadas em regiões (Region-based Convolutional Neural Networks, R-CNN)
- 3.0.7 Redes de conjugação em pirâmides espaciais (Spatial Pyramid Pooling networks, SPP-nets)
- 3.0.8 Redes convolucionais rápidas baseadas em regiões (Fast R-CNNs)
- 3.0.9 Redes convolucionais ainda mais rápidas baseadas em regiões (Faster R-CNNs)
- 3.0.10 Redes convolucionais baseadas em regiões com máscara (Mask R-CNNs)
- 3.1 Model Zoos de Outros…
- 4 Bases para Benchmarks e Competições
- 5 Artigos e Sites de Revisão
- 6 Referências para este Glossário
Conceitos
Entenda a babel de DL…
Arquiteturas de Redes
Redes neurais convolucionais (Convolutional neural networks, CNNs ou deep convolutional neural networks, DCNNs)
LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324. Original Paper PDF
Redes deconvolucionais (Deconvolutional networks, DNs, ou inverse graphics networks, IGNs)
Zeiler, Matthew D., et al. “Deconvolutional networks.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010. Original Paper PDF
Redes convolucionais gráficas inversas profundas (Deep convolutional inverse graphics networks, DCIGNs)
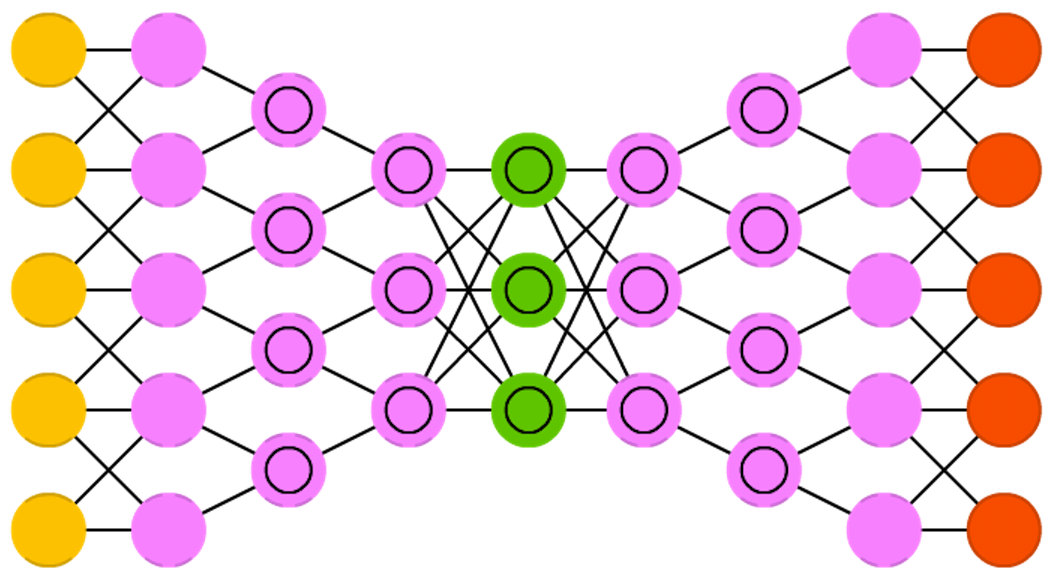
Redes neurais convolucionais (CNNs) têm sido utilizadas em muitas tarefas diferentes de processamento de imagens e visão computacional. Quando se trata da interpretação de imagens, podemos diferenciar 3 categorias de ações: (a) classificação de imagens, (b) detecção e localização de objetos em imagens e (c) segmentação de objetos em imagens de acordo com a sua classe ou categoria.
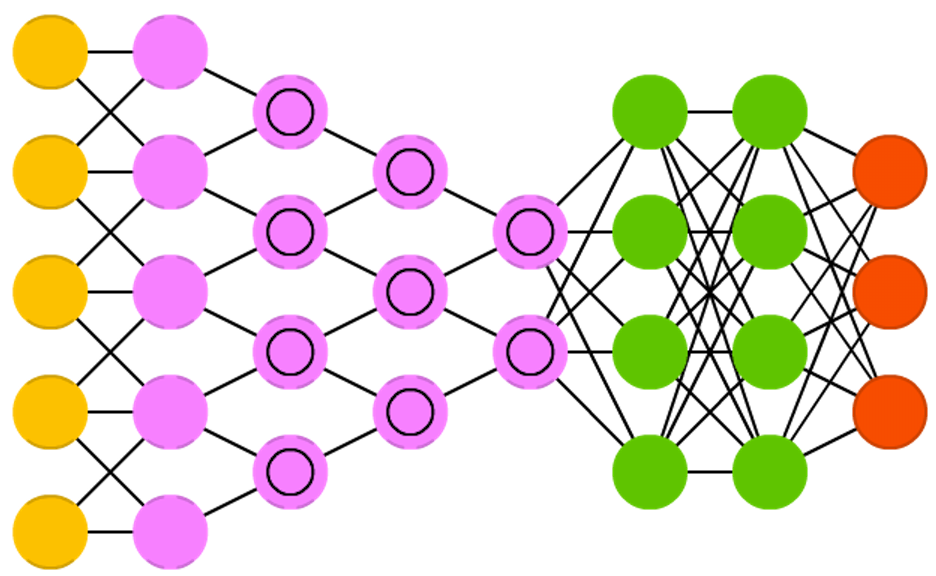
Esta última modalidade de aplicação de CNNs é denominada Segmentação Semântica e é modalidade para a qual DCIGNs são úteis. Redes para segmentação semântica classificam objetos em imagens e são capazes de associar pixels individiais das imagens à classe de objeto que representam, realizando na prática uma segmentação da imagem de acordo com a semântica do objeto ao qual cada pixel individual está associado.
Para isso essas redes neurais possuem uma arquitetura bastante típica, composta de uma etapa de classificação ou codificação e uma etapa de associação de rótulos a pixels ou decodificação, onde classificações são mapeadas de volta a pixels através de upsampling. Dependendo da arquitetura em particular, determinadas camadas das duas etapas da rede possuem conexões diretas ou atalhos. Esta estrutura é tipicamente representada em desenhos esquemáticos por um “U”.
A parte inicial da rede, encoder, é igual a uma arquitetura típica de uma rede convolucional de classificação de imagens. Entretanto, não possui as últimas camadas totalmente conectadas. Tipicamente, outra modificação na arquitetura consiste em ter um grande número de canais com caraterísticas extraídas conectados diretamente também à etapa de upsampling. Isso permite que a rede consiga propagar mais informações sobre contexto da imagem às camadas que estão “acima”, ou seja, de maior resolução.
Kulkarni, Tejas D., et al. “Deep convolutional inverse graphics network.” Advances in Neural Information Processing Systems. 2015. Original Paper PDF
Leia mais em: http://www.lapix.ufsc.br/ensino/visao/visao-computacionaldeep-learning/deep-learningsegmentacao-semantica#Modelos_Classicos
Autocodificadores variacionais (Variational autoencoders, VAEs)
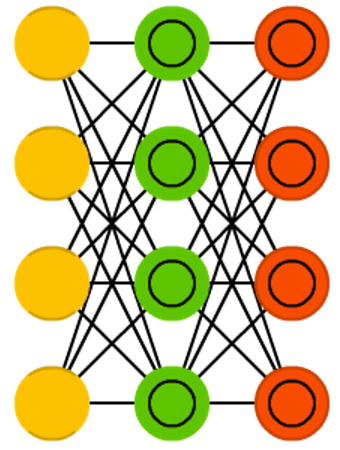
Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013). Original Paper PDF
Redes gerativas adversárias (Generative adversarial networks, GANs)
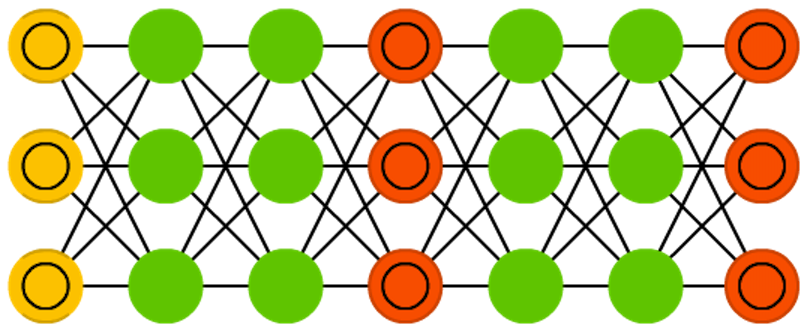
Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in Neural Information Processing Systems. 2014. Original Paper PDF
Redes neurais de transferência de estilo profundo (NST – Neural Style Transfer)

NST é uma técnica onde se trabalha uma imagem de entrada, uma imagem de conteúdo, e uma imagem de referência de estilo. A imagem de entrada costuma ser, inicialmente, uma cópia da imagem de conteúdo. O objetivo é iterativamente aplicar o estilo da imagem de referência de estilo à imagem de entrada, gerando uma nova imagem de saída, com o conteúdo da imagem de entrada e o estilo da imagem de referência de estilo.
Redes residuais profundas (Deep residual networks, DRNs)
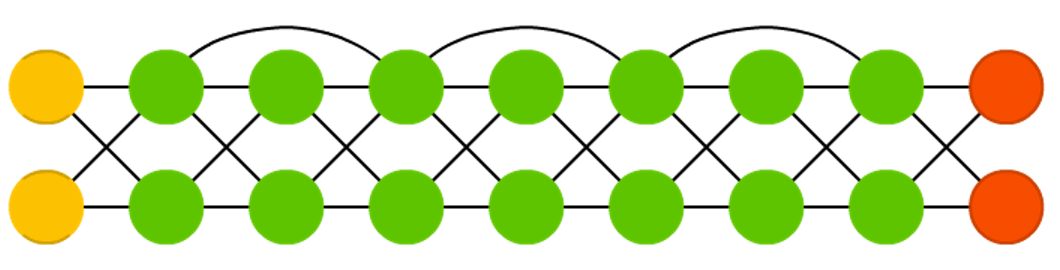
São modelos de redes que combatem a fuga de gradientes na retropropagação do erro através de módulos residuais.
- ResNet
- He, Kaiming, et al. “Deep residual learning for image recognition.” arXiv preprint arXiv:1512.03385 (2015). Original Paper PDF
- Towards Data Science: Vincent Fung. An Overview of ResNet and its Variants (2017)
Redes totalmente convolucionais (Fully Convolutional Network, FCN)
Detetores de objetos baseados em regressão (Regression-based object detectors ,RBODs)

YOLO (YOLO, You only Look Once)
Os enfoques tradicionais usam foco em sub-regiões da imagem para identificar objetos. A rede nunca olha para a imagem como um todo.YOLO considera a imagem como um todo. Em YOLO uma única rede convolucional prediz tanto os bounding boxes quanto as probabilidades de pertinencia a classe de cada objeto detectado. Para isso, YOLO funciona da seguinte forma:
- toma-se uma imagem e divide-se-a em um grid de tamanho SxS;
- usando o grid como referência, gera-se m bounding boxes;
- bounding boxes com probabilidade acima de um limiar são selecionados e usados para localizar o objeto dentro da imagem.
YOLO muito mais rápido (45 fps no set dos autores -> até duas ordens de grandeza) mais rápido do que algoritmos contemporâneos. Sua maior falha é inacurácia com objetos pequenos na imagem.
Veja mais aqui: http://www.lapix.ufsc.br/ensino/visao/visao-computacionaldeep-learning/deep-learningreconhecimento-de-imagens#You_Only_Look_Once_YOLO
Detetor de disparo único (Single-shot detector, SSD)
Elementos Arquiteturais, Funcionais e de Análise
Análise de Resultados e Métricas de Performance
Matriz de Confusão
Uma Matriz de Confusão ou Matriz dos Erros é uma tabela que permite visualizar a performance de um algoritmo de aprendizado supervisionado: Cada linha representa instâncias da classe predita pelo algoritmo, enquanto cada coluna representa as classes às quais a instância pertence de fato (de acordo com codificado no conjunto de teste/validação).
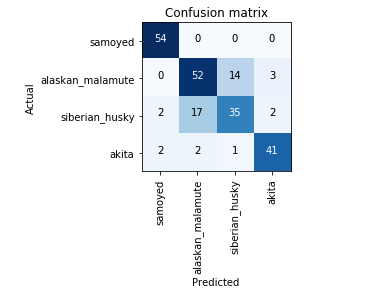
Links:
Usando Matrizes de Confusão com Keras:
- Medium::Build your First Deep Learning Neural Network Model using Keras in Python
- GitHub::RyanAkilos/A simple example: Confusion Matrix with Keras
- Stanford – Machine Learning Coding Tutorial::Keras Confusion Matrix / Validation Set
- Stackoverflow::Get Confusion Matrix From a Keras Multiclass Model
Verdadeiro Positivo, Verdadeiro Negativo, Falso Positivo e Falso Negativo
TP, TN, FP e FN não são métricas de performance, são parâmetros que calculamos e que serão usados para diferentes métyricas de performance. Qual o seu significado?
- Verdadeiro Positivo (TP) – a predição para X é positiva e X é de fato positivo => predição correta. Ex.: Predissemos que Fulano tem COVID-19 e ele de fato está doente;
- Verdadeiro Negativo (TN) – a predição para X é negativa e X é de fato negativo => predição correta. Ex.: Predissemos que Fulano não tem COVID-19 e ele de fato está saudável;
- Falso Positivo (FP) – a predição para X é positiva mas X é negativo => predição incorreta. Ex.: Predissemos que Fulano tem COVID-19 mas ele está saudável;
- Falso Negativo (FN) – a predição para X é negativa e X é de fato positivo => predição incorreta. Ex.: Predissemos que Fulano não tem COVID-19 e ele de fato está doente.
TP, TN, FP e FN estão intimamente ligados à Matrix de Confusão. Veja este artigo na Wikipedia para saber mais detalhes.
Acurácia
It’s the ratio of the correctly labeled subjects to the whole pool of subjects.
Accuracy is the most intuitive one.
Accuracy answers the following question: Quantos indivíduos eu rotulei corretamente do meu total de indivíduos?
Accuracy = (TP+TN)/(TP+FP+FN+TN)
numerator: all correctly labeled subject (All trues)
denominator: all subjects
Precisão
Precision is the ratio of the correctly +ve labeled by our program to all +ve labeled.
Precision answers the following: Quantos daqueles eu eu rotulei como doentes estão de fato doentes?
Precision = TP/(TP+FP)
numerator: +ve labeled diabetic people.
denominator: all +ve labeled by our program (whether they’re diabetic or not in reality).
Sensibilidade (Recall)
Recall is the ratio of the correctly +ve labeled by our program to all who are diabetic in reality.
Recall answers the following question: De todos que estão doentes, quantos eu predisse corretamente?
Recall = TP/(TP+FN)
numerator: +ve labeled diabetic people.
denominator: all people who are diabetic (whether detected by our program or not)
F1-score (F-Score / F-Measure)
F1 Score considers both precision and recall.
It is the harmonic mean(average) of the precision and recall.
F1 Score is best if there is some sort of balance between precision (p) & recall (r) in the system. Oppositely F1 Score isn’t so high if one measure is improved at the expense of the other.
For example, if P is 1 & R is 0, F1 score is 0.
F1 Score = 2*(Recall * Precision) / (Recall + Precision)
Especificidade
Specificity is the correctly -ve labeled by the program to all who are healthy in reality.
Specifity answers the following question: De todos os indivíduos doentes, quantos desses eu predisse corretamente?
Specificity = TN/(TN+FP)
numerator: -ve labeled healthy people.
denominator: all people who are healthy in reality (whether +ve or -ve labeled)
Interseção sobre União – IoU (Intersection over Union)
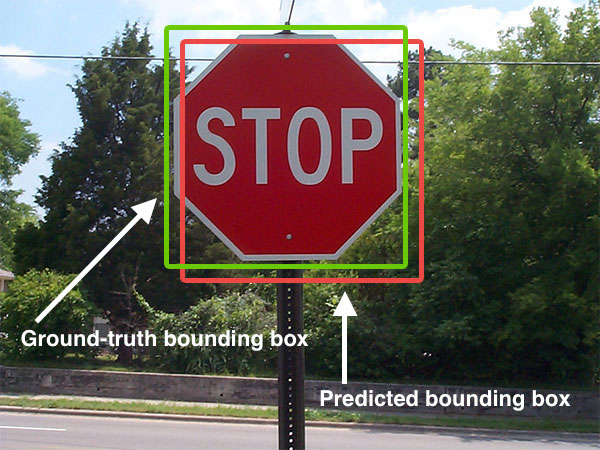
IoU é uma métrica para determinar a acurácia de um detetor de objetos. Usada na popular PASCAL VOC challenge. Ela é dada pela divisão da área de intersecção entre o bounding box encontrado e o bounding box do ground trutch pela área da união desses mesmos bounding boxes, como mostra a figura abaixo:
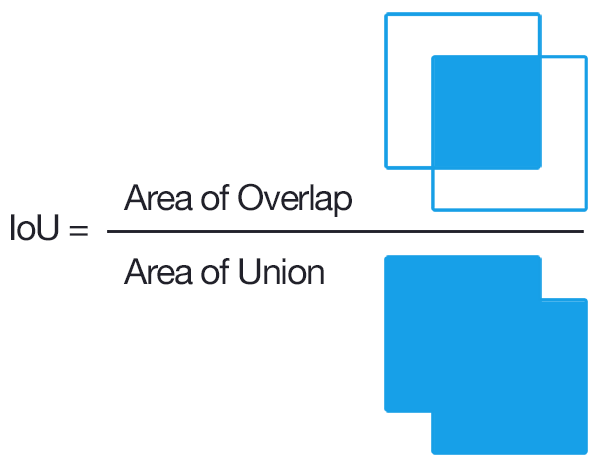
Link: PyImageSearch: Intersection over Union (IoU) for object detection
Elementos Funcionais
Não-linearidade: Funções de Ativação
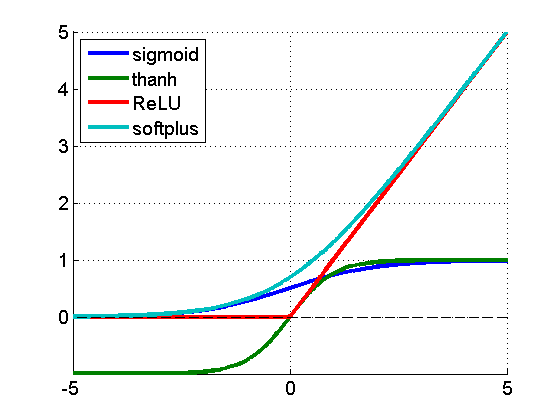
Revisão geral sobre funções de ativação em RNAs: Towards Data Science: Activation Functions: Neural Networks – Sigmoid, tanh, Softmax, ReLU, Leaky ReLU EXPLAINED !!!
Unidade linear retificada (Rectified Linear Unit, ReLu)

f(x) = max(0,x)
Um retificador linear é uma função que devolve zero para valores negativos e a identidade para valores positivos. É usada como uma alternativa de baixo custo computacional para as funções de ativação quaselineares função logística (sigmóide) ou tangente hiperbólica e especialmente também para a função softplus, abaixo. ReLu resolve o problema de gradientes evanescentes substituindo valores positivos pela identidade e valores negativos por zero. Isto bloqueia o efeito em cadeia de um valor baixo puxar outros da rede para baixo e tudo encalhar em zero.
Existe, porém, um problema com ReLus: podem ficar presas em um estado morto, quando uma mudança de pesoas grande faz a entrada de ReLu ser extremamente negativa e ReLu pular para um estado de “constante zero”. Você resolveu gradientes evanescentes mas inventou os Relus moribundos.
Unidade linear retificada com Vazamento (Leaky ReLu)
Uma solução para Relus moribundos é arriscar e permitir um gradiente bem pequeno (ex., 0.01) do lado negativo:
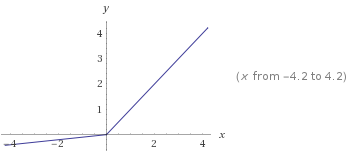
O quanto isso é arriscado? Quanto maior a inclinação da reta do lado esquerdo, maior é o risco de gradientes evanescentes. Você decide.
Unidades Lineares com Exponencial em Escala (Scaled Exponential Linear Units, SELUs)
Uma alternativa mais inteligente de resolver este problema são SELUs. SELUs são lineares do lado direito e possuem uma função que se aproxima de uma constante do lado esquerdo:
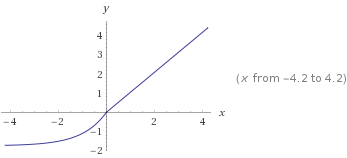
SELUs apareceram pela primeira vez em Setembro de 2017 no artigo Self-Normalizing Neural Networks de Günter Klambauer, Thomas Unterthiner, Andreas Mayr, Sepp Hochreiter, apresentado em Advances in Neural Information Processing Systems 30 (NIPS 2017).
SELUs são funções de ativação mostradas na figura acima. São calculadas de acordo com a fórmula:
![]()
SELUs possuem vantagens:
- permite redes neurais profundas porque não permitem gradientes evanescentes;
- diferentemente de ReLUs, SELUs não morrem;
- mostraram, na prática, que aprendem melhor e mais rápido do que outras funções de ativação.
Links:
- Apresentação: Towards Data Science: A first Introduction to SELUs and why you should start using them as your Activation Functions
- Discussão: Towards Data Science: SELU — Make FNNs Great Again (SNN)
- Artigo: Self-Normalizing Neural Networks de Günter Klambauer, Thomas Unterthiner, Andreas Mayr, Sepp Hochreiter
Softplus
Softplus é a função analítica dada pela fórmula adiante: e parece ser um modelo de função não-decrescente que descreve como humanos incorporam conhecimento anterior em novas decisões em sistemas de aprendizado.
Softmax
Quando estamos trabalhando com problemas de classificação e a CNN tem de ajudar você a decidir entre várias classes, podemos usar uma função que nos ajuda a mapear a resposta de uma rede neural para um conjunto de variáveis categóricas. Softmax vai sempre prover uma resposta onde (a) todos os resultados vão se encontrar no intervalo [0,1] e (b) a soma dos resultados é sempre igual a 1:
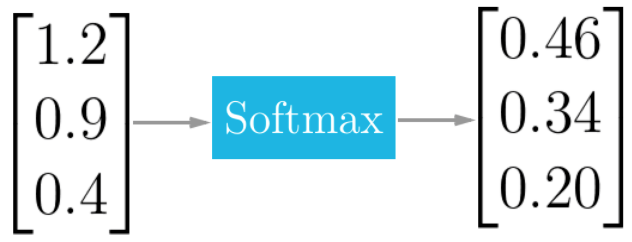
A saída da função softmax é igual à distribuição de probabilidade categórica, indicando a probabilidade de uma imagem pertencer/conter um objeto de determinada categoria. A fórmula de softmax é:

onde:
- z é o vetor com as saídas da última camada da rede neural (tem de ter a mesma dimensão K do número de classes)
- K é o número de classes
- σ é a saída de softmax
- j é a classe cuja probabilidade categórica se deseja calcular
Um detalhamento de softmax é dado aqui: https://en.wikipedia.org/wiki/Softmax_function.
Elementos Estruturais
Convolução, camada convolucional (Convolution, convolutional layer)
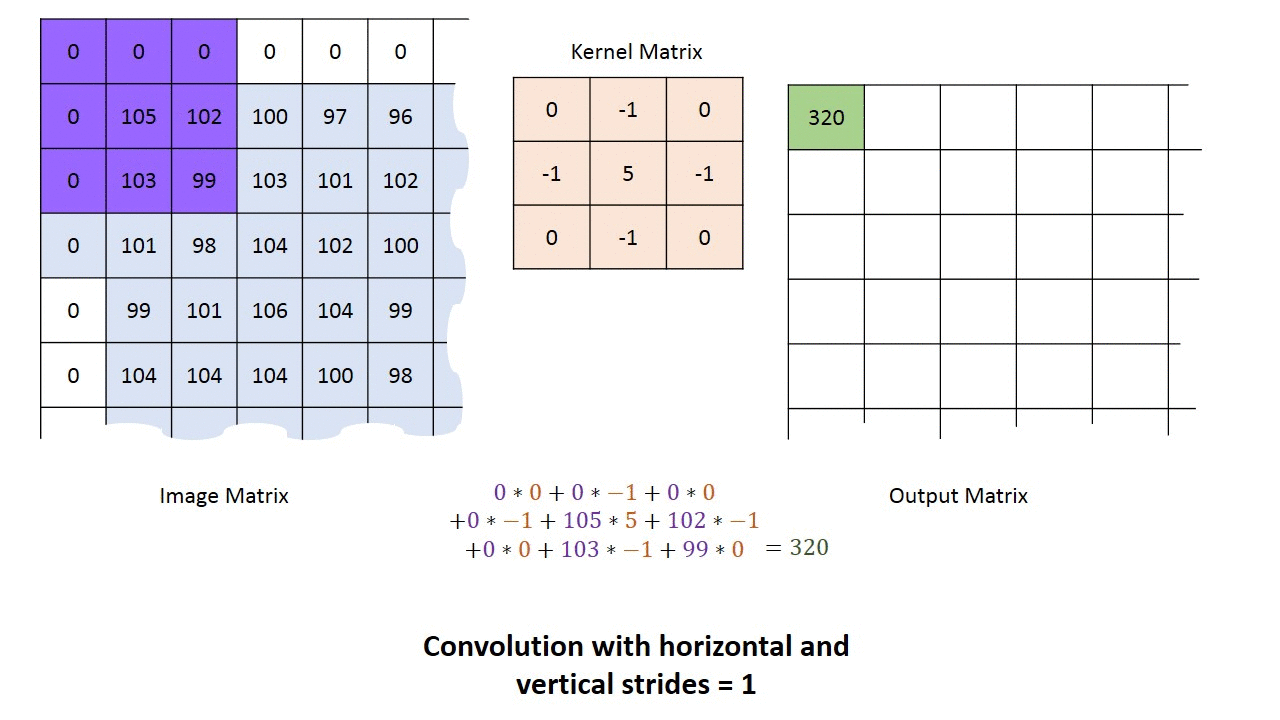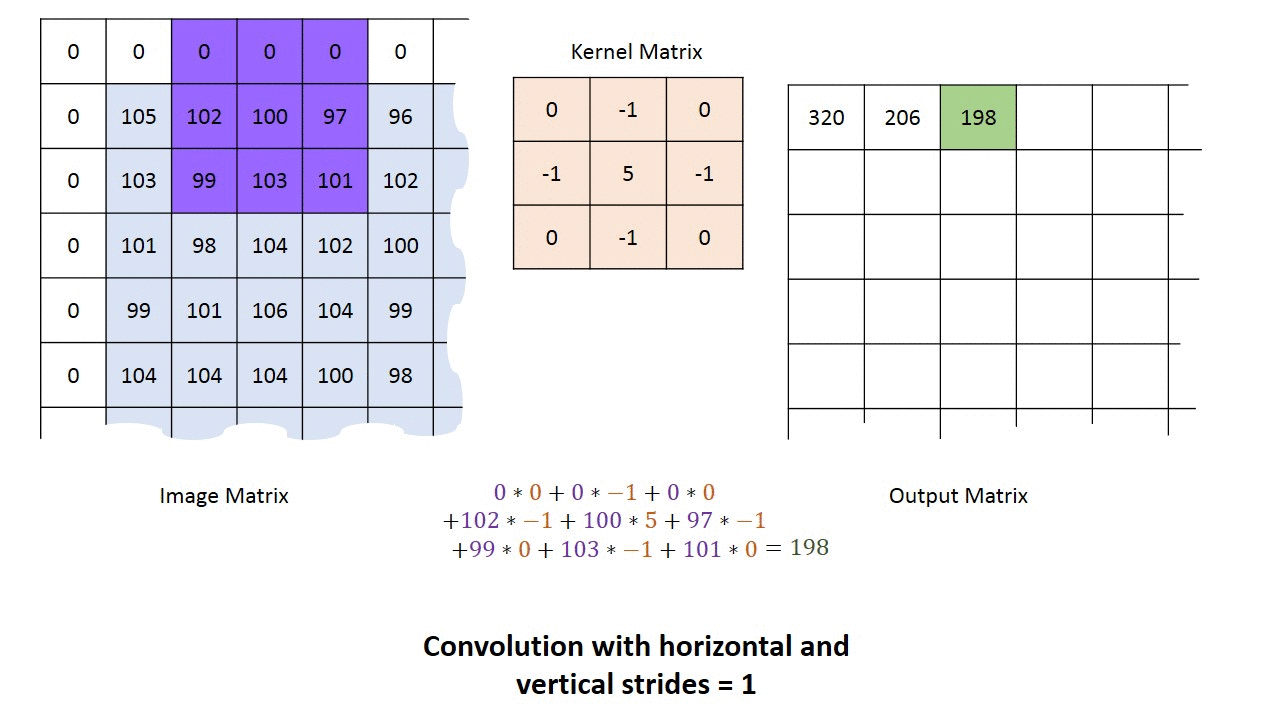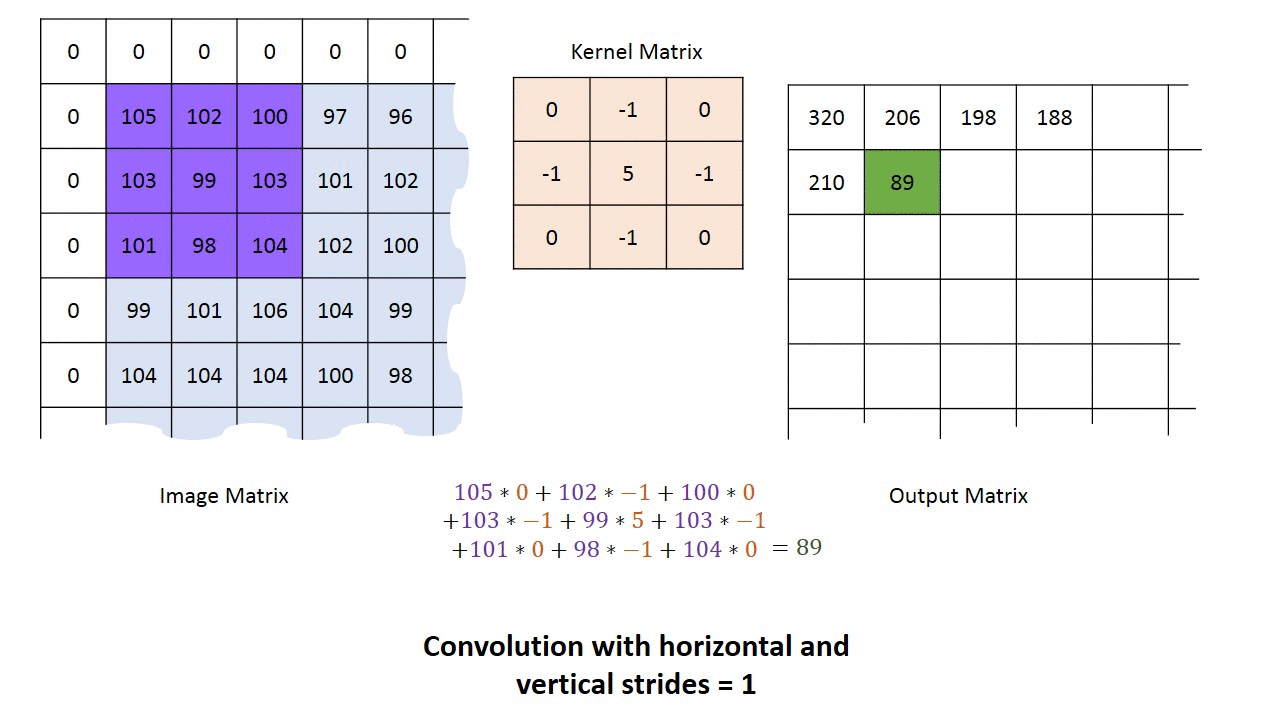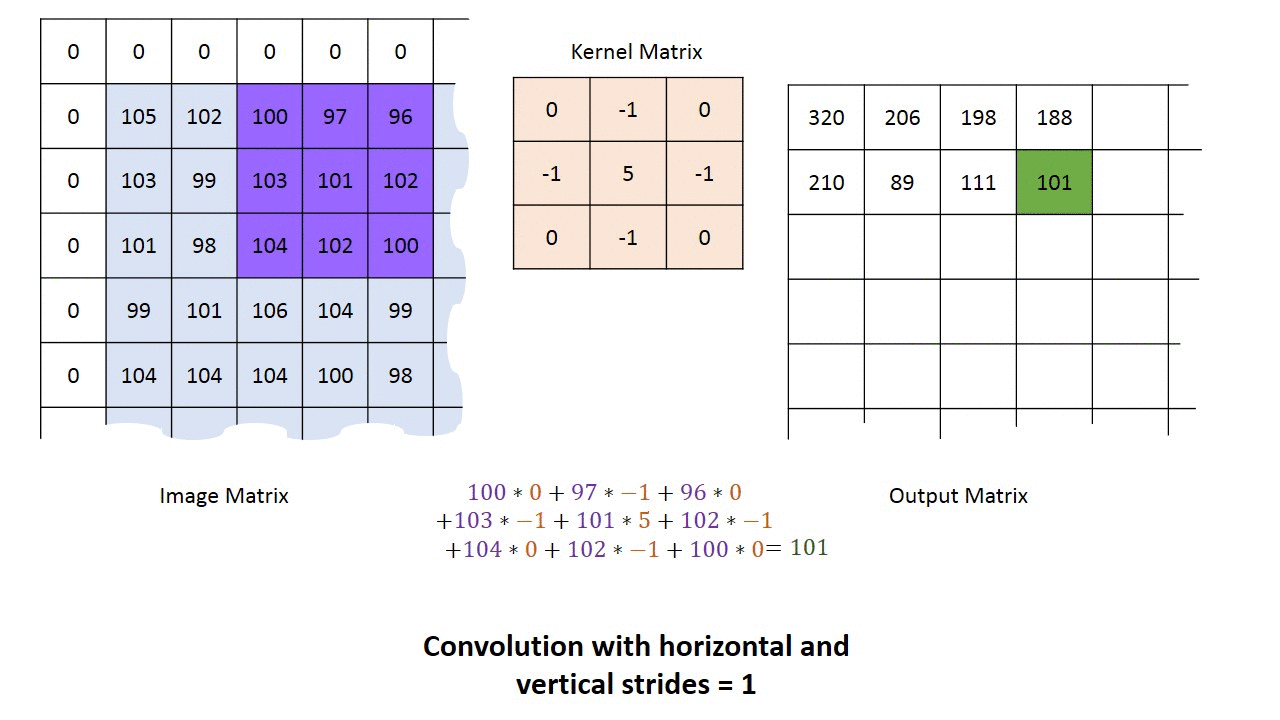
Camadas convolucionais podem ter 3 dimensões: profundidade, largura e altura. Largura e altura especificam o tamanho da camada e a quantidade de saídas que ela terá para codificar a ativação da camada anterior. A profundidade diz respeito ao número de filtros que ela aplica para cada janela de entrada. Podemos inicializar uma camada convolucional com vários filtros, que são aplicados de forma independente à camada anterior. A figura abaixo mostra uma camada convolucional de profundidade = 5.
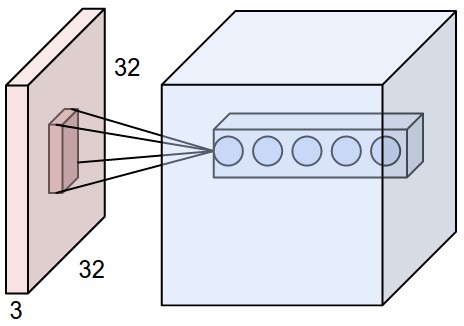
A saída tipicamente é a soma das ativações produzidas por cada um dos filtros. Você pode conectar esta camada a uma camada não-linear ou então usar uma função de ativação não-linear diretamente na saída.
Camadas convolucionais com kernels 1X1
Parece bobagem. Por que vou filtrar com um kernel 1×1? Mas pode ajudar traznendo tanto não-linearidade quanto redução de número de graus de liberdade (variáveis): um filtro 1×1 calcula uma combinação linear de um conjunto de saídas em todos os canais da camada anterior e pode ainda passar este resultado através de uma função de ativação não-linear. Veja a aula de Martin Görner da Google para uma explicação intuitiva.
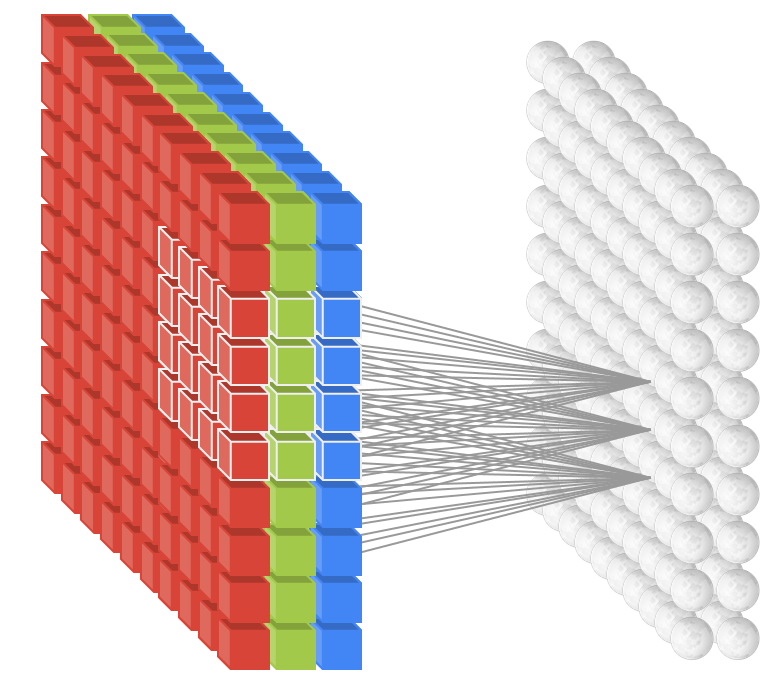
Camada convolucional multicanal (Multi-channel convolutional layer)

A figura abaixo mostra uma visualização estrutural de uma camada de entrada de 3 canais conectada a uma camada convolucional de profundidade 2 e que utiliza kernels 4×4: o kernel de cada um dos dois níveis da camada convolucional é aplicado a cada um dos três canais, seus resultados são somados e constituem a entrada do neurônio no nível correspondente.
Enchimento (Padding)
Para garantir que o centro de um kernel comnvolucional caia sobre todos os dados de entrada, usamos enchimento com zeros para as bordas da área a ser convolvida quando estamos convolvendo as bordas da de uma camada anterior. As figuras acima todas trabalham com enchimento = 1 pois o kernel é 3×3 e só necessita ter uma linha e uma coluna preenchidas com zeros.
Passada ou marcha (Stride)
É passo com o qual avança-se a matriz de convolução sobre a imagem ou camada anterior. No exemplo abaixo usamos uma passada de 2, indicando que o kernel é avançado 2 posições a cada vez que é aplicado. A maior passada que faz algum sentido é o tamanho do kernel.
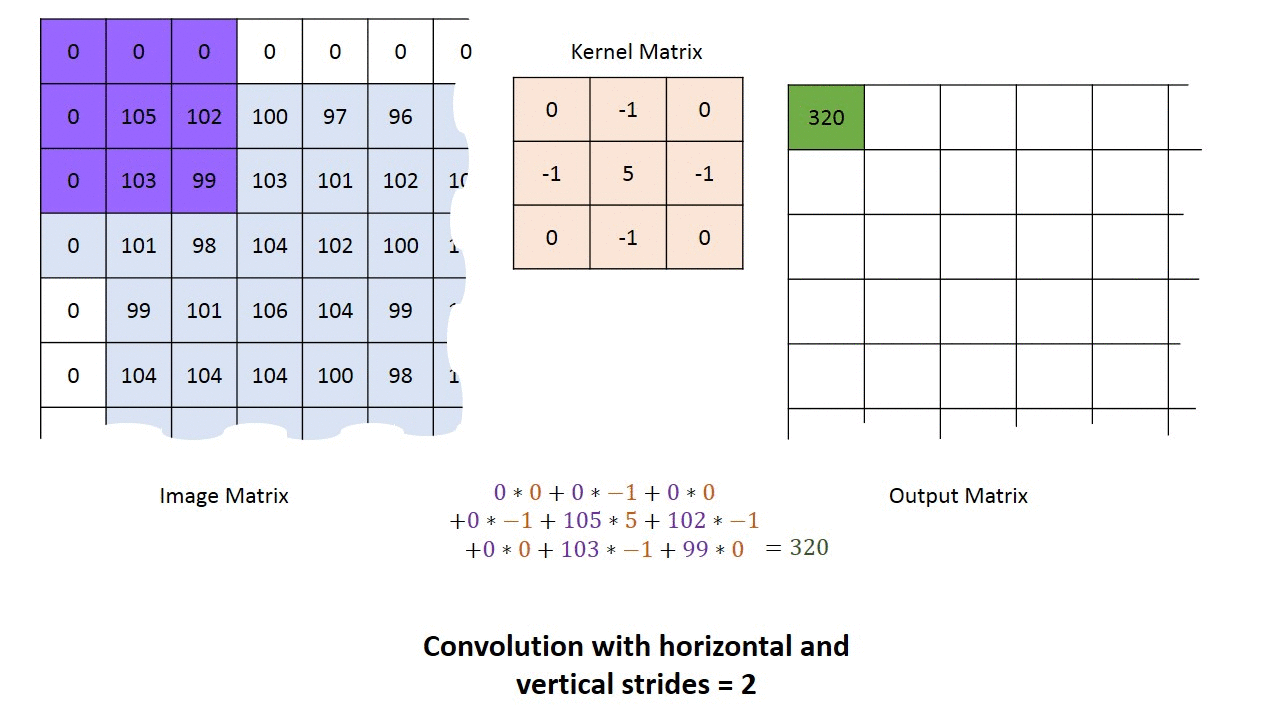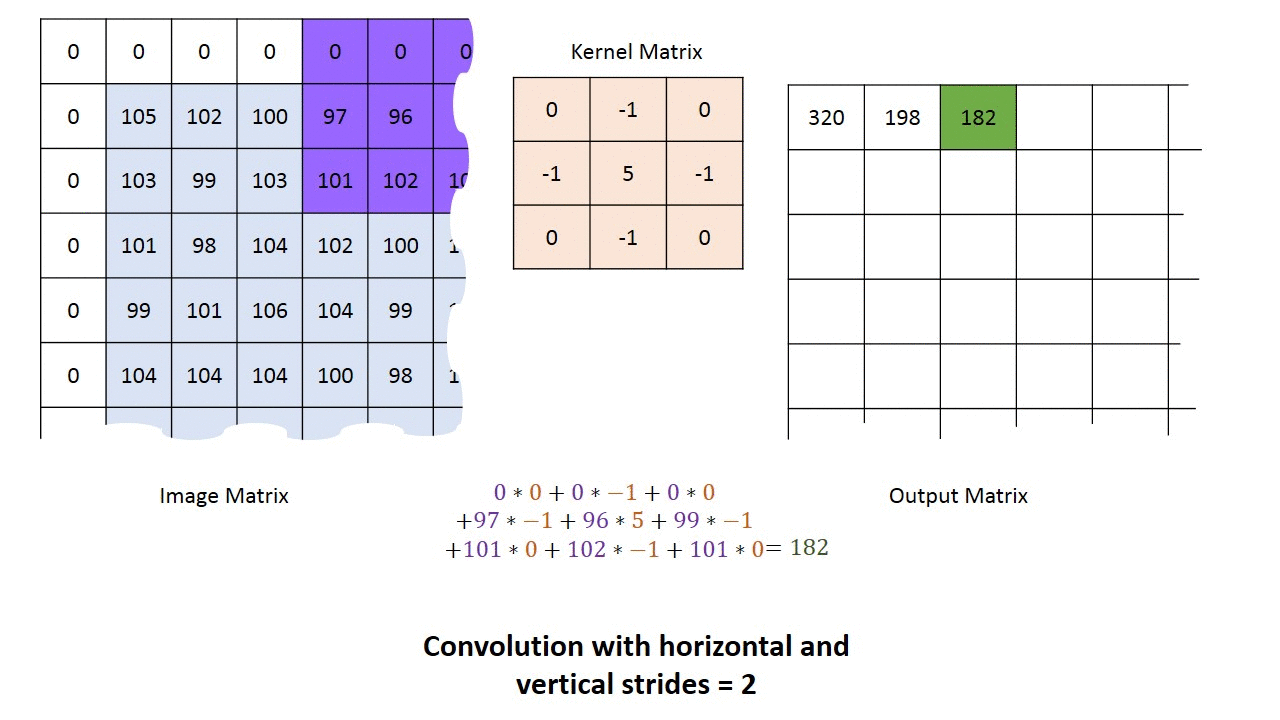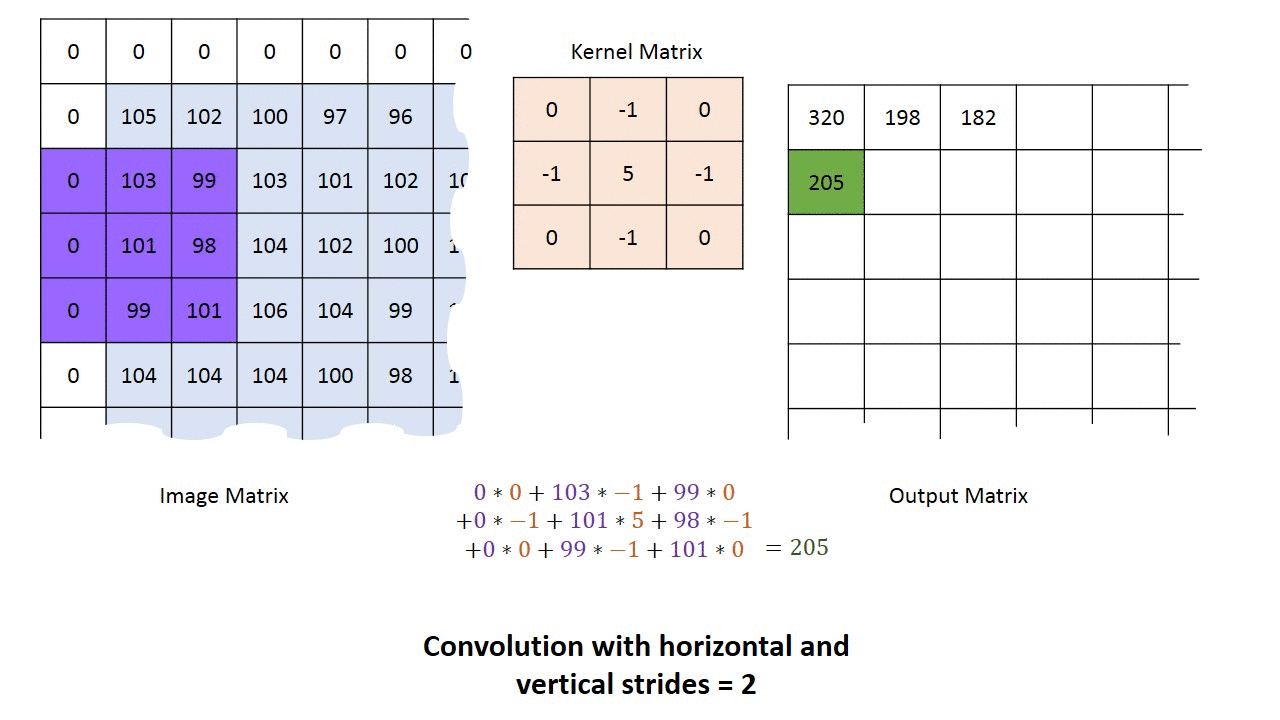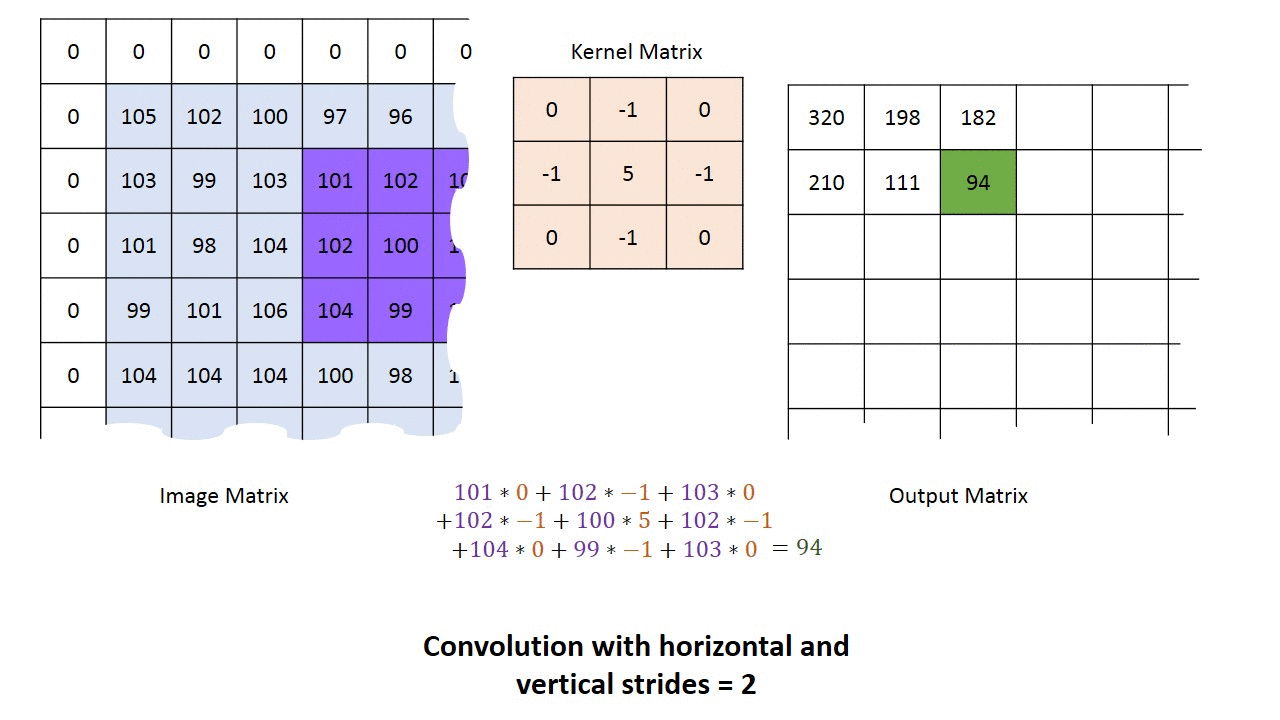
Conjugação máxima (Maximum pooling, max pooling)
Evanescimento ou fuga de gradientes e módulos residuais (gradient vanishing and residual modules)
Um problema com redes neurais muito profundas, é que, ao retropropagarmos o erro, a cada camada para a qual o erro é retropropagado vai ocorrer uma diminuição da intensidade dos gradientes retropropagados. Na prática isso reduz a intensidade do sinal de treinamento e, assim, o aprendizado, à medida em que voltamos ao início da rede. Camadas iniciais de uma rede muito profunda, dessa forma, aprendem apenas muito lentamente. Chamamos a este fenômeno de evanescimento ou fuga de gradientes.
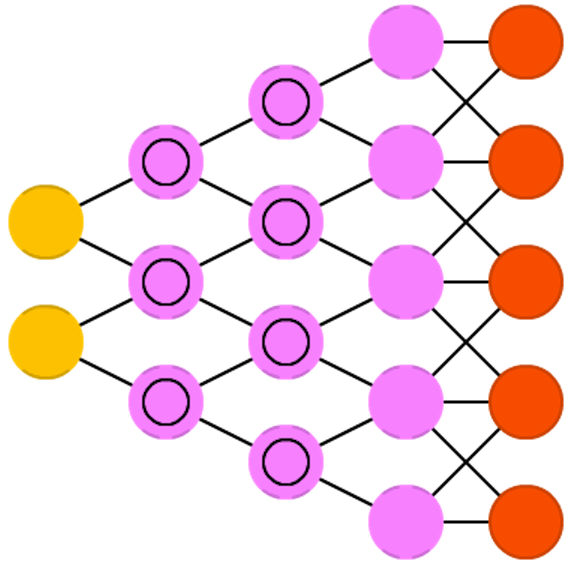
Desconsideração de neurônios (Drop-Out, dropout)
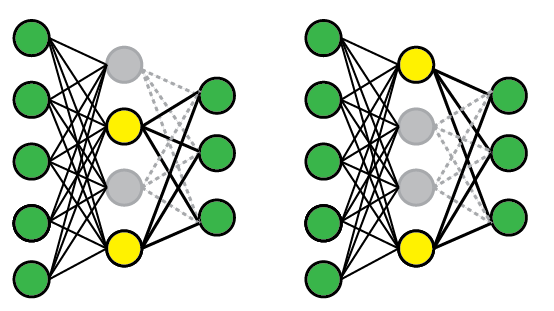
Dropout é uma técnica para prevenir a co-adaptação de neurônios: queremos estimular unidades a aprender a extrair e representar caracterísitcas dos dados de entrada sem depender de seus vizinhos e produzir uma representação excessivamente distribuída. Para isso randomicamente selecionamos conjuntos diferentes de neurônios e os forçamos a ter saída nula para diferentes dados de entrada. Na prática isso de fato retira os neurônios da rede nessa iteração do treinamento. Na figura acima temos uma situação onde, em uma apresnetação dos dados neurônios 2 e 4 são utilizados e na outra os neurônios 1 e 4 são usados. Em fase de teste usamos todos e compensamos os pesos para refletir o número total de neurônios ativo. Outro efeito é, na prática, não estamos treinando uma rede, mas um conjunto de redes, com várias configurações. Isto provoca uma regularização do modelo que reduz as chances de sobreadaptação (overfitting).
Desconsideração de conexões (Drop-Connect, dropconnect)
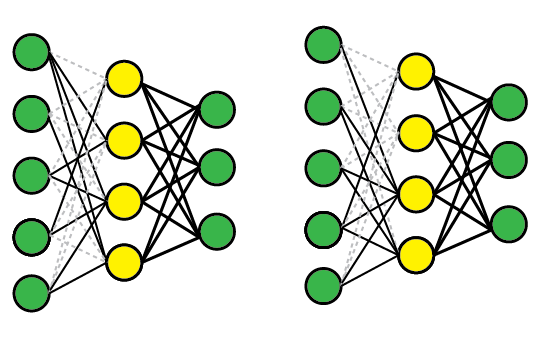
Dropconnect é outra técnica para prevenir a co-adaptação de neurônios: queremos estimular unidades a aprender a extrair e representar caracterísitcas dos dados de entrada sem depender de seus vizinhos e produzir uma representação excessivamente distribuída. Para isso randomicamente selecionamos conjuntos diferentes de pesos de conexõese os forçamos a ter valor nulo para diferentes dados de entrada. Na prática isso de fato retira essas conexões da rede nessa iteração do treinamento. Diferentemente do dropout, porém, essa técnica permite aos neurônios ficarem parcialmente ativos durante o processo. Em fase de teste usamos todas as conexões e compensamos os pesos para refletir o número total de conexões ativa. Outro efeito é, na prática, não estamos treinando uma rede, mas um conjunto de redes, com várias configurações. Isto provoca uma regularização do modelo que reduz as chances de sobreadaptação (overfitting).
- DropConnect: Wan et al., 2013
Modelos
Model Zoo: Redes Famosas
Aqui abordamos alguns modelos famosos de Redes Neurais Convolucionais para processamento de imagens.
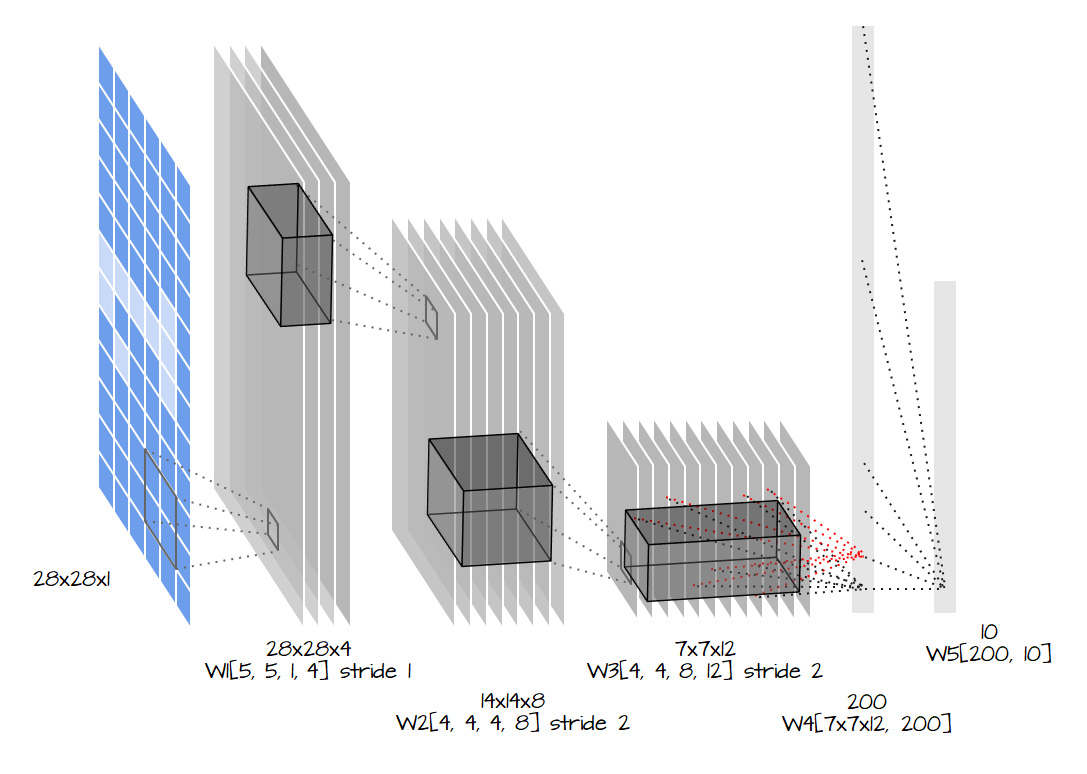
AlexNet
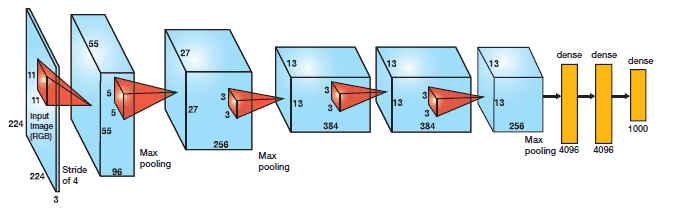
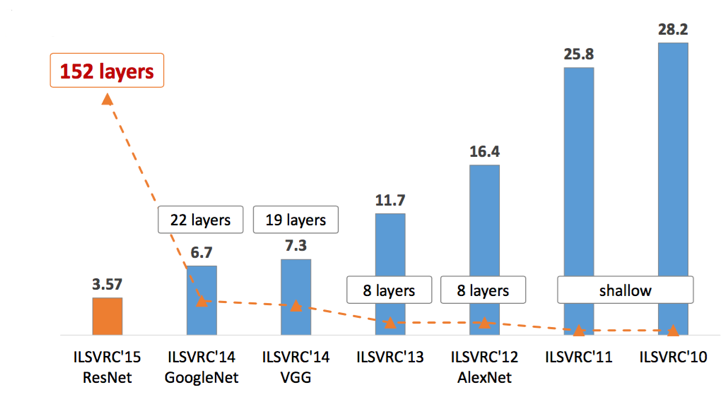
Em 2012, AlexNet ultrapassou de forma significativa todos os outros competidores e venceu a competição Large Scale Visual Recognition Challenge (ILSVRC) de 2012 reduzindo o top-5 error de 26% para 15.3%. O top-5 error do segundo colocado, que não foi uma variação de CNN, foi de 26.2%.
A rede possui uma arquitetura muito similar à LeNet desenvolvida por Yann LeCun mas é muito mais profunda, com mais filtros por camada e com camadas convolucionais sobrepostas. Ela consistiu de convoluções 11×11, 5×5,3×3, max pooling, dropout, data augmentation, ReLU activations e SGD com momento. Utilizou ReLU activations depois de cada camada convolucional e também depois de cada camada completamente conectada (backpropagation tradicional).
Veja mais em: http://www.lapix.ufsc.br/ensino/visao/visao-computacionaldeep-learning/deep-learningreconhecimento-de-imagens#AlexNet
VGGNet
A competição Large Scale Visual Recognition Challenge (ILSVRC) de 2014 observou o aparecimento de duas novas propostas de CNNs. GoogLeNet e VGGNet.
VGGNet foi desenvolvida por Simonyan and Zisserman e o seu modelo mais conhecido é composto por 16 camadas convolucionais. É um modelo muito elegante por sua uniformidade de arquitetura. Possui similaridades a AlexNet, mas utiliza apenas convoluções 3×3 e as compensa com muitos filtros. A rede foi treinada em 4 GPUs por 2 a 3 semanas.
VGGNet é considerada a rede preferida pela comunidade para aprendizado pro transferência pois sua arquitetura uniforme é boa para extrais características de imagens. Assim, VGG tem sido utilizada como extrator de características-base para muitas outras coisas, como Unet, TernausNet e várias outras redes.
VGG16 no entanto, possui 138 milhões de parâmetros, o que a torna uma rede ruim para treinar a partir do zero.

Veja mais em: http://www.lapix.ufsc.br/ensino/visao/visao-computacionaldeep-learning/deep-learningreconhecimento-de-imagens#VGG
ResNet
ResNet foi apresentada na ILSVRC 2015, a qual ela venceu com uma performance no top-5 error rate de 3,57%. A Rede Neural Residual (ResNet) apresentada por Kaiming He et al introduziram uma nova arquitetura com duas características principas:
- “identity shortcut connections”: uma estratégia de “atalhos” ou “conexões de salto” que pulam pares de grupos de camadas convolucionais. São também chamadas gated units ou gated recurrent units, apesar de não apresentarem uma recorrência no sentido tradicional dos modelos de redes neurais recorrentes;
- foco pesado em normalização de lotes (batch normalization).
Graças a este enfoque eles foram capazes de treinar uma rede com até 152 camada, mas que possuía uma complexidade final menor do que VGG.
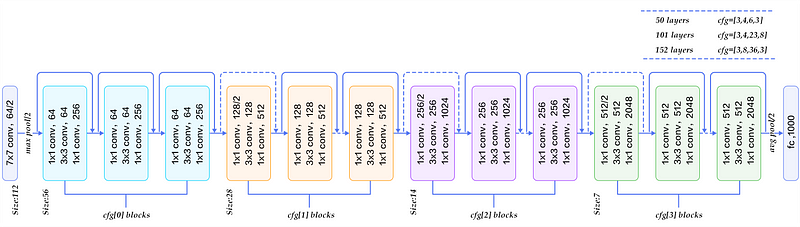
Arquitetura de ResNet50
Veja mais em: http://www.lapix.ufsc.br/ensino/visao/visao-computacionaldeep-learning/deep-learningreconhecimento-de-imagens#ResNet
GoogLeNet/Inception (ou Inception V1)
O vencedor da competição Large Scale Visual Recognition Challenge (ILSVRC) de 2014 foi GoogleNet(a.k.a. Inception V1) da Google, obtendo um top-5 error de apenas 6.67%!
Isto estava muito próximo da performance humana, a qual so organizadores da competição passaram a ter de avaliar. Essa avaliação é difícil de executar e experimentos demonstraram que, para bater a acurácia de GooGleNet, treino dos participantes era necessário. Após alguns dias de treino, um especialista humano (Andrej Karpathy – Tesla Automóveis) foi capaz de atingir um top-5 error de 5.1%(simples) e 3.6%(ensemble).
GooGleNet usa um modelo de CNN inspirado por LeNet, mas que implementou um novo conceito: o módulo de incepção. Ela usou batch normalization, distortions das imagens e RMSprop. O módulo de incepção é baseado em várias convoluções pequenas com o objetivo de drasticamente reduzir o número de parâmetros e facilitar o treinamento . GooGleNet possui uma arquitetura de 22 camadas, mas reduziu o número de parâmetros de 60 milhões (AlexNet) para 4 milhões.
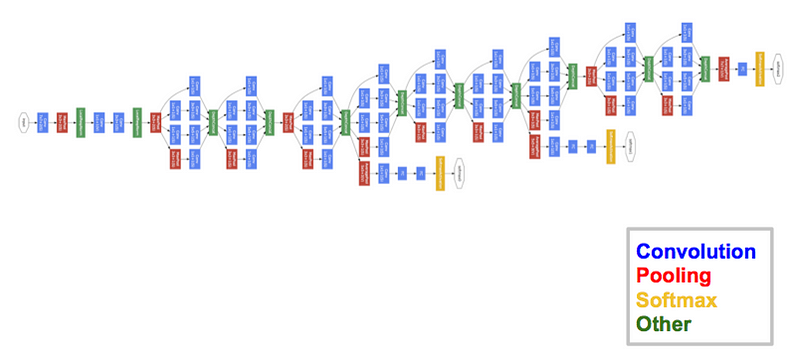
Arquitetura de GooGleNet (Inception V1)
Inception V3
Inception V2 e V3 foram propostas no mesmo artigo. Várias melhorias foram apresentadas e, na prática, hoje utiliza-se Inception V3.
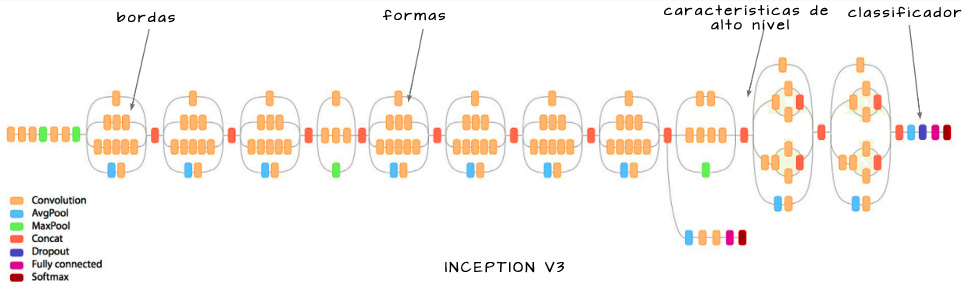
Todas as melhorias apresentadas são refinamentos a nível de detalhe: conceitualmente não há grande diferença entre Inception V1, V2 e V3. Chama a atenção
- introdução dos módulos de incepção heterogêneos (desenvolvidos mais em Inception V4);
- redução das saídas auxiliares a apenas uma (descobriu-se que só possuem influência significativa próximo do final do treinamento).
Veja mais em: http://www.lapix.ufsc.br/ensino/visao/visao-computacionaldeep-learning/deep-learningreconhecimento-de-imagens#Inception_V2_V3
Redes convolucionais baseadas em regiões (Region-based Convolutional Neural Networks, R-CNN)
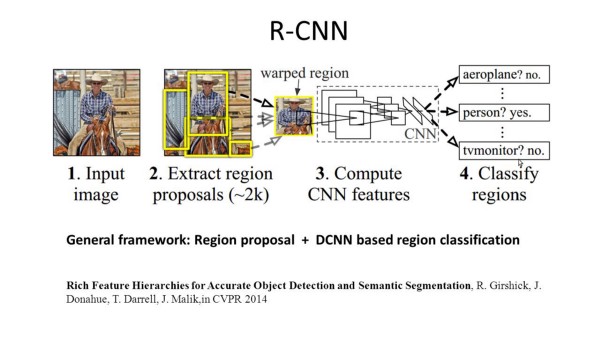
R-CNN executa segmentação com base nos resultados da detecção de objetos. R-CNN inicialmente usa busca seletiva para extrair uma grande quantidade de candidatos e então calcula as características para cada um deles através de CNN. Por fim classifica cada região usando um classificador linear específico, geralmente SVM (suport vector machines). Ao contrário das redes discutidas na seção anterior, R-CNN é capaz de executar tarefas mais complexas, como detecção de objetos e segmentação grosseira de imagens. Uma R-CNN pode ser construída sobre qualquer das redes de classificação de imagens tradicionais, como AlexNet, VGG, GoogLeNet e ResNet.
Redes de conjugação em pirâmides espaciais (Spatial Pyramid Pooling networks, SPP-nets)
Link: SPP-Net (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
Redes convolucionais rápidas baseadas em regiões (Fast R-CNNs)
Em um artigo no ano seguinte, os autores da R-CNN apresentaram uma solução que resolve os problemas de lentidão do enfoque baseado na análise de 2000 imagens semi-randômicas do R-CNN: preprocessamento convolucional.
Ao invés de alimentar a rede neural com imagens-candidatas, a imagem inteira é alimentada à rede para a geração de um mapa de caracterísiticas convolucionais (CFM – convolutional feature map). Este CFM é então usado para a busca por regiões-candidatas, que são reformatadas em imagens quadradas de tamanho fixo através de uma camada de pooling de região de interesse (RoI pooling). A partir do vetor de características gerado para cada RoI é realizada uma classificação com uma camada softmax, que prediz a categoria do objeto e a associa ao bounding box dado pelo quadrado de origem.
Redes convolucionais ainda mais rápidas baseadas em regiões (Faster R-CNNs)
Uma solução encontrada, novamente parcialmente pelos mesmos autores da R-CNN e da Fast_R-CNN, para tornar a rede ainda mais rápida, foi eliminar a busca seletiva por regiões de interesse. Similarmente à Fast R-CNN, a imagem é usada diretamente como entrada para gerar um mapa de características convolucional. Neste modelo, porém, ao invés de realizar uma busca seletiva sobre este mapa, uma segunda rede neural, separada, é usada para predizer regiões candidatas. É chamada de Region Proposal Network (RPN). RPN usa uma mini-rede neural baseada em uma janela deslizante que analisa a imagem de entrada e é invariante a translação. Para evitar excesso de propostas, supressão de não-máximos é realizada já neste estágio.
Essas regiões-candidatas, da mesma forma que no Fast-R-CNN, são reformatadas em imagens quadradas de tamanho fixo através de uma camada de pooling de região de interesse (RoI pooling). A partir do vetor de características gerado para cada RoI é realizada uma classificação com uma camada softmax, que prediz a categoria do objeto e a associa ao bounding box dado pelo quadrado de origem.
Redes convolucionais baseadas em regiões com máscara (Mask R-CNNs)
Mask R-CNN. Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick arXiv.org > cs > arXiv:1703.06870 (2018) Original paper PDF
Model Zoos de Outros…
- Model Zoo: Discover open source deep learning code and pretrained models
- ONNX Model Zoo: collection of pre-trained, state-of-the-art models in the ONNX format
- Caffe Model Zoo
Bases para Benchmarks e Competições
ImageNet
The ImageNet project is a large visual database designed for use in visual object recognition software research. The ImageNet project runs an annual software contest, the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), where software programs compete to correctly classify and detect objects and scenes.
PASCAL VOC – Visual Object Classes
The PASCAL VOC project: http://host.robots.ox.ac.uk/pascal/VOC/
- Provides standardised image data sets for object class recognition
- Provides a common set of tools for accessing the data sets and annotations
- Enables evaluation and comparison of different methods
- Ran challenges evaluating performance on object class recognition (from 2005-2012, now finished)
- Leaderboards for the Evaluations on PASCAL VOC Data
Pascal VOC data sets: Data sets from the VOC challenges are available through the challenge links below, and evalution of new methods on these data sets can be achieved through the PASCAL VOC Evaluation Server. The evaluation server will remain active even though the challenges have now finished.
Microsoft COCO – Common Objects in COntext
COCO is a large-scale object detection, segmentation, and captioning dataset. COCO has several features: Object segmentation, Recognition in context, Superpixel stuff segmentation, 330K images (>200K labeled), 1.5 million object instances, 80 object categories, 91 stuff categories, 5 captions per image and 250,000 people with keypoints.
COCO:
- Site: http://cocodataset.org
- Artigo: Microsoft COCO: Common Objects in Context – Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollár
- GitHub: https://github.com/nightrome/cocostuff
CIFAR-10 e CIFAR-100
CIFAR-10 e CIFAR-100 são subconjuntos anotados do 80 million tiny images dataset. Foram coletados por Alex Krizhevsky, Vinod Nair e Geoffrey Hinton.É usado como referência para treinamento de muitos modelos de CNNs.
- Site: https://www.cs.toronto.edu/~kriz/cifar.html
- Competição no Kaggle: CIFAR-10 – Object Recognition in Images
- Tutorial: Towards Data Science – CIFAR-10 Image Classification in TensorFlow
- Github: https://github.com/EN10/CIFAR
Kaggle
Kaggle é uma comunidade internacional de cientistas de dados e pesquisadores em Aprendizado de Máquina, famosa por suas competições de aprendizado de máquina, onde problemas específicos com datasets associados são postados e times de diferentes instituições e empresas competem para tentar resolver. Passou também a oferecer uma plataforma pública para armazenamento de datasets e um ambiente de oficina de aprendizado de máquina baseado em nuvem. Me Março de 2017 Google anunciou a aquisição de Kaggle, que continua a operar nos antigos moldes.
- Site: https://www.kaggle.com/
- Competições: this was Kaggle’s first product and still what the site is most famous for. Companies post problems and machine learners compete to build the best algorithm. In addition, Kaggle also has:
- Kaggle Kernels: a cloud-based workbench for data science and machine learning. Allows data scientists to shore code and analysis in Python and R. Over 150K “kernels” (code snippets) have been shared on Kaggle covering everything from sentiment analysis to object detection.
- Datasets: community members share datasets with each other. Has datasets on everything from bone x-rays to results from boxing bouts.
- Kaggle Learn: cursos de IA de curta duração.
Alibaba Tianchi
Plataforma de Ciência de Dados e Aprendizado de Máquina do provedor de e-commerce Alibaba. Similar ao Kaggle, oferece competições, plataforma de deep learning, datasets, cursos e oportunidades de emprego.
- Site: https://tianchi.aliyun.com/
- Competições: https://tianchi.aliyun.com/competition/gameList.htm
- Plataforma de aprendizado de máquina: https://tianchi.aliyun.com/notebook/index.htm
InnoCentive
Empresa de inovação de crowdsourcing que também oferece competições e desafios similares ao Kaggle.
- Site: https://www.innocentive.com/
- Desafios/competições: https://www.innocentive.com/ar/challenge/browse
Carvana Image Masking Challenge
Carvana (https://www.kaggle.com/c/carvana-image-masking-challenge) é uma competição de segmentação semântica: o objetivo é corretamente extrair a imagem de um carro de seu pano de fundo em uma cena qualquer. Esta competição oferece um prêmio de USD 25.000,00 ao melhor colocado.
Artigos e Sites de Revisão
- Revisão dos Modelos: The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches, 2018
- Revisão focada em Imagens:
- Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Waseem Rawat and Zenghui Wang. Neural Computation
Volume 29 | Issue 9 | September 2017, p.2352-2449 - Srinivas, S., Sarvadevabhatla, R. K., Mopuri, K. R., Prabhu, N., Kruthiventi, S. S., & Babu, R. V. (2016). A taxonomy of deep convolutional neural nets for computer vision. arXiv 1601.06615
- Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Waseem Rawat and Zenghui Wang. Neural Computation
- Medium: CNN Architectures: LeNet, AlexNet, VGG, GoogLeNet, ResNet and more ….
- CV-Tricks: ResNet, AlexNet, VGGNet, Inception: Understanding various architectures of Convolutional Networks
Referências para este Glossário
- The Neural Network Zoo – The Asimov Institute
- The Machine Learning Zoo – UNSW DataSoc
- Revisão dos Modelos: The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches, 2018
- Revisão focada em Imagens: Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Waseem Rawat and Zenghui Wang. Neural Computation
Volume 29 | Issue 9 | September 2017, p.2352-2449 - Medium: CNN Architectures: LeNet, AlexNet, VGG, GoogLeNet, ResNet and more ….
- CV-Tricks: ResNet, AlexNet, VGGNet, Inception: Understanding various architectures of Convolutional Networks
- Medium: What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?
- Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD
- Hackernoon: Understanding YOLO
- Medium: SSD object detection: Single Shot MultiBox Detector for real-time processing
- Medium: What do we learn from single shot object detectors (SSD, YOLOv3), FPN & Focal loss (RetinaNet)?
- https://stats.stackexchange.com/questions/201569/difference-between-dropout-and-dropconnect
- Machine Learning Guru: Undrestanding Convolutional Layers in Convolutional Neural Networks (CNNs) – A comprehensive tutorial towards 2D Convolutional layers
- Medium: Understanding of Convolutional Neural Network (CNN) — Deep Learning
- Towards Data Science: The Deep Learning(.ai) Dictionary
- Towards Data Science: R-CNN, Fast R-CNN, Faster R-CNN, YOLO — Object Detection Algorithms
Copyright © 2018 Aldo von Wangenheim/INCoD/Universidade Federal de Santa Catarina